2024年国际计算语言学协会北美分会年会全文录用CCIIP实验室22级研究生李文迪同学(导师:魏巍)的论文“Reinforcement Learning with Token-level Feedback for Controllable Text Generation”为Findings。 2024年国际计算语言学协会北美分会年会(NAACL 2024)计划于2024年7月16日-7月21日在墨西哥召开。NAACL是CCF推荐的B类国际学术会议,在自然语言处理领域享有较高的学术声誉。
标题:Reinforcement Learning with Token-level Feedback for Controllable Text Generation (NAACL 2024 Findings)
作者:Wendi Li, Wei Wei*, Kaihe Xu, Wenfeng Xie, Dangyang Chen, Yu Cheng
内容简介:针对大型语言模型(LLM)文本生成可控性问题,先前研究试图将强化学习(RL)引入文本可控生成过程,然而当前RL方法通常以粗粒度(句子/段落级别)反馈为指导,但句子语义通常存在递进或转折,因此仅依赖粗粒度指导往往导致次优性能问题。为解决该问题,提出了一种新的强化学习算法TOLE,通过利用贝叶斯公式推导出TOken-Level的奖励,并采用“先分段后加噪”范式来增强强化学习鲁棒性,此外TOLE可以以极小代价灵活扩展到多个约束。实验结果表明,所提算法在单属性控制和多属性控制任务中均能取得优异性能。
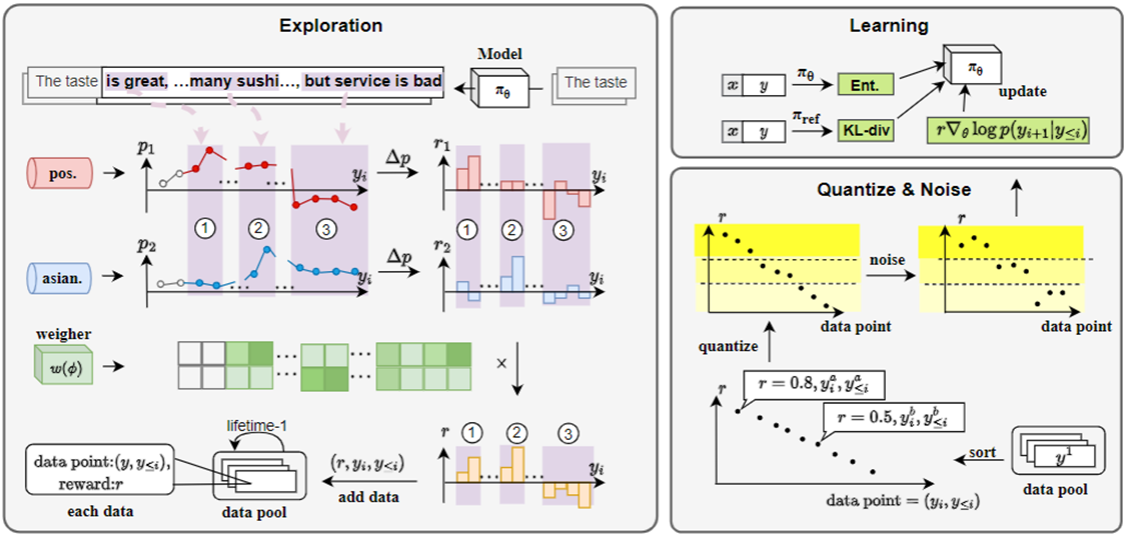
图1 TOLE算法框架:(1)通过奖励模型(通常可用特征分类器代理)计算出单个token对对应期望属性贡献;(2)在多重约束下,利用轻量级weigher权衡多个奖励模型间权重以计算最终奖励;(3)对于单个token奖励,将全局奖励分段并在段内进行随机扰动,并与KL散度/概率熵值同时迭代学习