自然语言处理与智能计算

主要研究如何使计算机有效处理和理解人类自然语言的相关基础理论和分析方法,其是当前人工智能领域在认知智能层面解决人机交互需要重点突破和解决的核心难点问题之一,其研究涵盖:自然语言处理基础理论(如分词、句法分析、语义理解、篇章分析、指代消歧等)、机器翻译、信息抽取与过滤、信息检索、知识表示与推理、多源异质文本数据分析与挖掘等。本方向是计算机科学、语言学、数学、逻辑学、认知科学等多学科领域的交叉方向,通过将自然语言处理与云计算、社交计算、物联网等相关领域研究进行深度融合,为人工智能与大数据处理技术在医疗、电子政务、互联网金融等相关行业方面的应用落地提供重要技术支撑,从而有效推动我国信息领域科学技术进步与中文信息处理产业发展。
成果展示:
智能人机对话系统---小希(取CCIIP首字母谐音,基于GPT2.0开发)
多模态融合与智能感知

主要从事多模态信息的智能感知与认知理论方法的研究,实现对真实开放环境下自然场景下的多模数据智能感知与理解,针对数据模态异质性、数据标签不完整性,数据分布不均衡性等特点,围绕多模信息表征与理解、跨媒体关联理解、多模/跨模感知融合等核心问题,全面研究智能感知的机理和方法,及多模数据智能融合处理等关键技术,打造完整的多模态融合与智能感知理论和技术体系。本方向是计算机视觉、自然语言处理以及音、视频信号处理等多学科领域的交叉方向。因此,团队将在语音识别与生成、图片描述生成(Image Caption)、跨模检索(Cross-modal Retrieval)、视觉问答(Visual Question Answering, VQA)、指向性目标检(Referring Expression Comprehension,REC)、视频片段理解等问题上展开深入研究,其中涉及众多计算机视觉与自然语言处理领域挑战性难题,如视觉关系推理(Visual Reasoning)、先验语义偏差(Language Bias)及外部知识融合等。
大数据处理与智能推荐
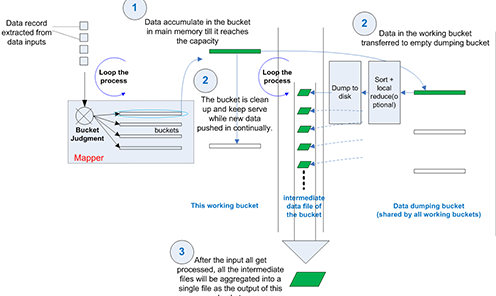
现有互联网环境下存在大规模原始异质数据,如何有效将现实社会应用场景与虚拟互联网进行深度融合以实现数据感知(如数据特征抽取等),同时挖掘其中存在的隐式依赖关系以识别出相关语义知识,以实现认知层面的人机交互(如语义理解、行为理解、情绪识别等)是本研究的核心关键。因此,团队在大数据分布式计算模型和框架、大数据知识表示与推理、智能问答/智能推荐等方面展开了深入研究:
提出一种基于朴素贝叶斯概率模型的多档分类算法用于复杂知识结构文档目录整合(发表于AAAI’11);
通过引入先验知识及异质属性信息,提出一种基于离散马尔科夫模型的半监督图排序算法实现对十亿级规模图数据排序(发表于SIGKDD’11及TCYB’16,图1为大规模分布式图排序计算框架),该工作在2017年被澳大利亚科技大学Dacheng Tao教授(IEEE Fellow)团队引用;
通过引入微博中多重异质关系及分组信息,提出一种基于拉普拉斯正则项的半监督专家排序算法用于微博主题专家查找(发表于TKDE’16),该工作被美国UCLA大学Wei Wang教授团队follow;
通过在核函数中引入用户历史访问点临近位置兴趣分布,提出一种基于协同过滤的个性化感兴趣点推荐算法(发表于CIKM’14),该工作在2017年被美国UCLA大学Jiawei Han教授(IEEE/ACM Fellow)团队引用,同时在VLDB’17论文“An experimental evaluation of point-of-interest recommendation in location-based social networks”中被评为迄今为止在该问题上性能最好的三个工作之一。