ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)是世界数据挖掘领域的顶级学术会议,由 ACM 的数据挖掘及知识发现专委会(SIGKDD)主办,被中国计算机协会和清华大学计算机学院推荐为A类会议。
本届KDD2021是在新加坡举行,整个议程包括议程包括主题演讲、专题小组、特邀报告、精选研究、workshop 等。大会共计收到 1541 篇有效投稿,其中 238 篇论文被接收,接收率为 15.4%,相比去年的接收率 16.9% 有所下降。受疫情影响,本次KDD 2021大会于2021年8月14日至18日在线上举办。认知计算与智能信息处理实验室(CCIIP)主任魏巍老师担任了本次KDD大会的Poster Chair,负责筹备与组织本次大会的Poster Session。本界SIGKDD大会是在新加坡虚拟社区Gather Town中展示Poster。在虚拟小镇中,参会者操纵的虚拟小人在其中寻找自己感兴趣的工作,论文作者在自己的论文海报面前向世界各地研究者介绍自己的研究成果。此外,实验室的张睿晗,邹定,余逸婷,潘为燃以及温笑非同学作为志愿者参与了KDD 2021大会的服务工作。

SIGKDD 2021组委会

基于Gather Town的Poster Session
8月5日,ACM SIGKDD 2021正式公布了最佳论文奖,Runner Up奖、新星奖、研究时间检验奖、应用数据科学时间检验奖、创新奖和服务奖。其中斯坦福大学的Aditya Grover获得最佳论文奖,UIUC 的Shweta Jain获得Runner Up奖,莱斯大学的华人学者胡侠获得新星奖。
研究方向最佳论文
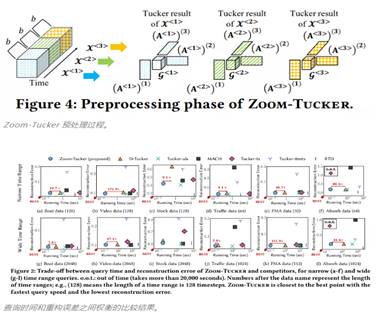
「研究方向最佳论文奖」由来自首尔大学的 Jun-gi Jang、U Kang 摘得,获奖论文是《Fast and Memory-Efficient Tucker Decomposition for Answering Diverse Time Range Queries》。

论文摘要:给定一个时间密集张量和一个任意的时间范围,我们如何有效地在这个范围内得到潜在因子?Tucker 分解是分析密集张量以发现隐藏因子的基本工具,已在许多数据挖掘应用中得到应用。然而,现有的分解方法不提供分析特定范围的时间张量的功能。现有的方法是 one-off 形式,主要集中在对整个输入张量执行一次 Tucker 分解。尽管现有的一些预处理方法可以处理时间范围查询,但它们仍然非常耗时,并且准确率较低。
在该论文中,该研究提出了 Zoom-Tucker,这是一种快速且节省内存的 Tucker 分解方法,可用于在任意时间范围内查找时间张量数据的隐藏因子。Zoom-Tucker 充分利用块结构来压缩给定的张量,支持有效查询并捕获本地信息。Zoom-Tucker 通过精心解耦包含在该范围内的预处理结果并仔细确定计算顺序,快速且高效地回答各种时间范围查询。研究证明,与现有的方法相比 Zoom-Tucker 的速度快 171.9 倍,所需空间少 230 倍,同时提供了相当的准确率。
研究方向最佳学生论文
来自维也纳大学计算机学院的 Ylli Sadikaj 等人获得了研究方向最佳学生论文,获奖论文是《Spectral Clustering of Attributed Multi-relational Graphs》。

论文摘要:图聚类旨在发现节点的自然分组,以便将相似的节点分配到一个公共集群。已有一些研究提出了面向多种图的多种算法,包括简单图、节点含有相关属性的图,以及对于边代表不同类型关系的图等。然而,许多领域中的复杂数据可以同时表征为属性网络和多关系网络。在该论文中,研究者提出了 SpectralMix,这是一种用于具有分类节点属性的多关系图的联合降维技术。SpectralMix 集成了来自属性、关系类型和图结构的所有可用信息,以实现对聚类结果的合理解释。此外,SpectralMix 泛化了现有方法:当仅应用于单个图时,它简化为频谱嵌入和聚类,当应用于分类数据时转换为同质性分析。该研究在几个现实世界的数据集上进行了实验,以检测图结构和分类属性之间的依赖关系,并展示了 SpectralMix 相比于现有方法的优势。
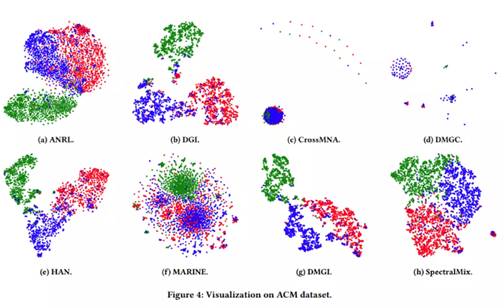
上图是几种模型在 ACM 数据集上实验结果的可视化。从中我们可以观察到 ANRL、CrossMNA、DMGC 和 MARINE 表现不佳,因为属于不同研究领域的节点被混到了一起;而 SpectralMix、DMGI、HAN 和 DGI 能够更好地区分不同类型的节点。很明显,SpectralMix 能够将不同研究领域的节点以更清晰的边界和更多的节点数目进行正确的聚类。此外,在图 4(h) 中嵌入的 SpectralMix 节点上值得注意的是,右侧有一组不同的节点,代表噪声数据或异常值,这表明 SpectralMix 对异常值具有稳健性。
应用数据科学方向最佳论文奖
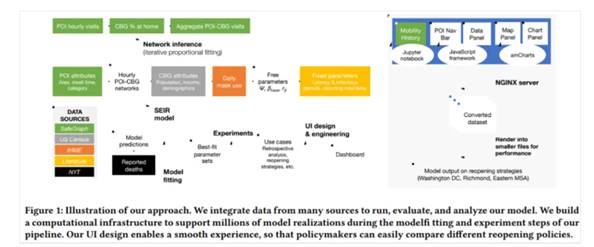
「应用数据科学方向最佳论文奖」由来自斯坦福大学等机构的 Serina Chang 等人摘得,获奖论文是《Supporting COVID-19 policy response with large-scale mobility-based modeling》。

论文摘要:移动性限制(Mobility restriction)一直是控制 COVID-19 传播的主要干预措施,但它们也给个人和企业带来经济负担。为了平衡这些相互竞争的需求,决策者需要分析工具来评估不同的移动性措施带来的成本和收益。
在该论文中,研究者介绍了与弗吉尼亚卫生部在决策支持工具上的互动所激发的工作,该工具利用大规模数据和流行病学模型来量化移动性变化对感染率的影响。该研究模型通过使用细粒度的动态移动网络来捕获 COVID-19 的传播,该网络对人们每小时从社区到各个地方的移动进行编码,每小时有超过 30 亿条边。通过扰乱移动网络,该研究可以模拟各种各样的重新开放计划,并预测它们在新感染和每个部门的访问量损失方面的影响。为了在实践中部署这个模型,该研究构建了一个具有鲁棒性的计算基础设施来运行数百万个模型,并且该研究与政策制定者合作开发了一个交互式仪表板(dashboard),用于传达模型对数千个潜在政策的预测。
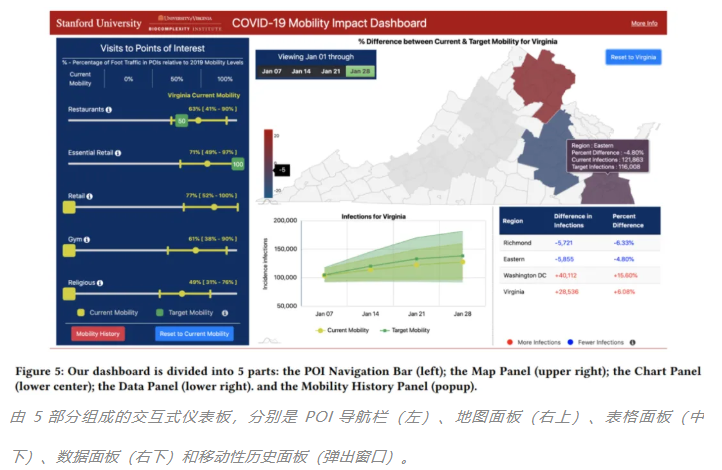
应用数据科学方向最佳论文亚军
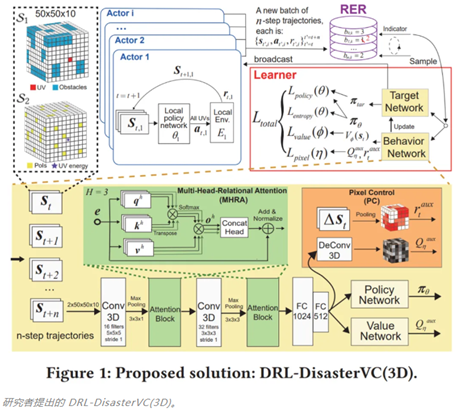
北京理工大学和美的集团的 Hao Wang、Chi Harold Liu 和 Jian Tang 等人获得了应用数据科学方向最佳论文亚军,获奖论文是《 Energy-Efficient 3D Vehicular Crowdsourcing For Disaster Response by Distributed Deep Reinforcement Learning 》。

论文摘要快速有效地访问环境和生活数据是成功应对灾害的关键。由无人机和无人驾驶汽车等无人驾驶交通工具 (UV) 组成的车辆众包 (VC) 从兴趣点 (PoI) 收集数据,例如可能有幸存者的地点和火灾现场,这提供了一种有效的方式来协助灾难救援。在该论文中,研究者考虑了在 3D 灾难工作区中导航一组 UV,以最大限度地提高收集的数据量、地理公平性、能源效率,同时最大限度地减少由于传输速率有限而导致的数据丢失。
该研究提出了一种分布式深度强化学习框架 DRL-DisasterVC(3D),该框架带有重复经验回放 (RER) 以提高学习效率,并使用裁剪目标网络来提高学习稳定性。该研究使用具有多头关系注意力 (MHRA) 的 3D 卷积神经网络进行空间建模,并且添加辅助像素控制 (PC) 进行空间探索。研究者设计了一种名为「DisasterSim」的新型灾难响应模拟器,并进行了大量实验,以表明当改变 UV、PoI 和 SNR 阈值的数量时,DRL-DisasterVC(3D) 在能效方面优于实验中所有 5 个基线方法。