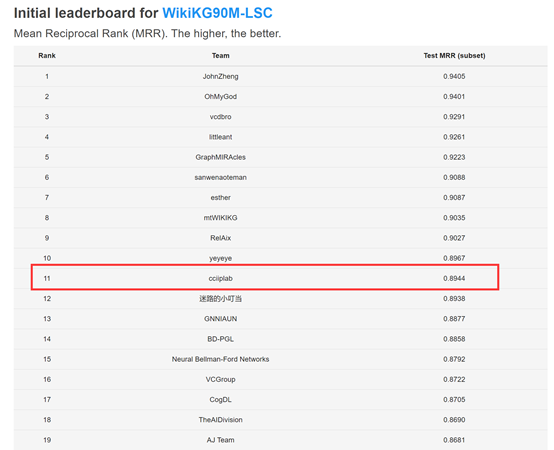
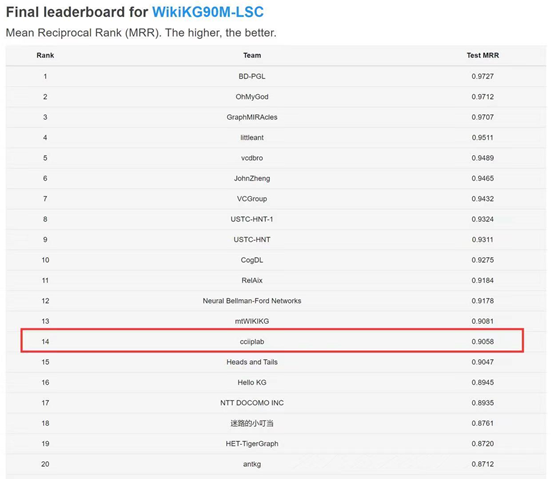
2021年6月9日,经过紧张激烈的角逐,“KDD Cup 2021” 结果提交截止,华中科技大学认知计算与智能信息处理(CCIIP)实验室参赛团队喜获佳绩,在OGB大规模图机器学习赛道中超大规模知识图谱上(8000万+实体,1000+关系和5亿+三元组)进行链接预测任务上取得了终榜第14名,初榜第11名的成绩。自2021年3月16日启动报名并发布数据,在本任务共有来自全球高校及工业界的39支队伍在初榜提交结果,28支队伍在终榜提交结果,包括中国科学技术大学、哈尔滨工业大学、西安交通大学、北京大学、弗吉尼亚大学、波士顿大学等国内外知名高校,以及科技企业阿里巴巴、百度、NTT DOCOMO等。比赛第一名最终由来自百度公司的队伍斩获。在历时近3个月的比赛时间里,CCIIP实验室的参赛队员们在实验室算力资源不足的困难下,坚持不懈努力,经过不断讨论,尝试了各种模型和优化方案,以终榜14名(初榜11名)的成绩为这次的参赛经历画上了句号。虽然最终未能跻身前十之列,但这是实验室首次参加在超大规模知识图谱上的比赛,且在资源受限条件下(仅用了一块3090 GPU显卡)对超大规模知识图谱进行处理,很好地锻炼了实验室同学们处理大规模数据、优化加速模型和解决知识图谱问题的能力。
KDD CUP 2021是由ACM知识发现和数据挖掘特别兴趣小组组织的年度数据挖掘和知识发现竞赛。今年比赛和去年类似,共设三个赛道,分别对应数据挖掘的不同领域:大规模图机器学习赛道、基于多数据集的时序异常检测和城市大脑挑战-交通网络调度。
其中,大规模图机器学习赛道由斯坦福大学的 Jure Leskovec 教授团队组织,基于其开源的大规模图谱数据集OGB-LSC。赛道共提供三个数据集(MAG240M、WikiKG90M、PCQM4M),要求选手在节点级别、边级别和图级别分别完成相应的预测任务,即节点分类、链接预测和图回归。
实验室团队选择的参赛题目为大规模图机器学习赛道的链接预测(Link Prediction)任务,要求参赛者根据给定的头实体和关系,对知识图谱中给定的1001个候选尾实体进行排序,选出最匹配的尾实体作为答案。
近年来,由于图结构数据在实际应用中的盛行,图上的机器学习 (ML) 引起了极大的关注。现代应用领域包括网络规模的社交网络、推荐系统、超链接的网络文档、知识图 (KG) 以及由不断增加的科学计算生成的分子模拟数据等。虽然现有的图表示模型GNN在较小规模的图上取得了很好的效果,但在大规模数据上却面临着复杂度过高、难以优化等挑战。因此,在本次任务中,斯坦福大学的Jure Leskovec教授团队提供了涵盖各领域的丰富数据,三元组规模达十亿级,用以参赛者进行模型训练,以推动图机器学习在大规模数据上的应用和发展。
排名网址:OGB-LSC @ KDD Cup 2021 | Open Graph Benchmark (stanford.edu)
下图为比赛官网在WikiKG90M数据集上的最终结果排行:
竞赛详情介绍
1. 竞赛任务
在验证和测试阶段,给定头实体head和关系relation,参赛者的目标是预测出正确的尾实体tail。具体来说,需要对给定的1001个候选尾实体进行排序,尽可能地将正确的尾实体排在靠前的位置。最终的结果指标为MRR@10,将正确答案排在第i位 (1≤i≤10) 得到1/i的分数。
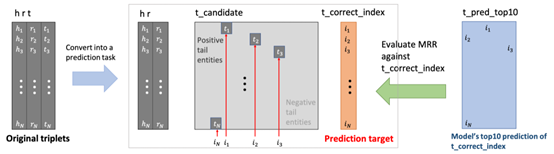
2. 数据简介
本次竞赛使用了斯坦福大学Jure Leskovec基于维基百科数据构造的大规模知识图谱WikiKG90M。他们选择2020年9月的维基百科版本用于构造训练集,共包含87143637种实体,1315种关系和504220369个三元组。验证集和测试集分别取自2020年10月和11月新增的维基数据,验证集中的每个三元组都包含1000个负样例和1个正样例,用于参赛者的本地评估;测试集的每个三元组同样提供1001个候选尾实体,但正确答案不包含在本地文件中,参赛者提交后可在平台服务器上进行结果验证。初榜包含5%的测试数据,终榜则使用了全部的测试数据。
WikiKG90M数据的规模如下图中第2行所示: