CCIIP实验室2018级本科实习生陈扬意、粟锦同学(2020年12月加入实验室,导师:魏巍)论文“Multi-granularity Textual Adversarial Attack with Behavior Cloning”及2021级研究生潘为燃同学(2021年9月入学,导师:魏巍)论文“Context-aware Entity Typing in Knowledge Graph”被自然语言处理顶级国际会议EMNLP 2021(Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing)分别作为长文全文及Findings录用。2021届国际自然语言处理大会(EMNLP 2021)计划于2021年11月7日-11月9日在多米尼加共和国(蓬塔卡纳)Barceló Bávaro 会议中心召开。EMNLP虽然是CCF推荐的B类国际学术会议,但是在自然语言处理领域享有很高的学术声誉,在国外学术界与ACL具有同等学术地位。
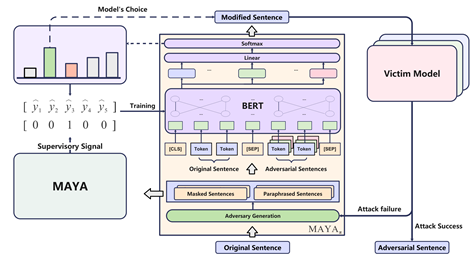
1. Multi-granularity Textual Adversarial Attack with Behavior Cloning,Yangyi Chen, Jin Su, Wei Wei*,In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'2021), Punta Cana, Dominican Republic.
内容简介:近年来,文本对抗攻击模型持续获得广泛的关注,其可用于评估NLP模型的鲁棒性、构造对抗样本进行数据集的增广,以及暴露模型在真实场景下部署可能存在的安全隐患。然而,这些攻击模型存在着一些明显的不足:1、攻击模型只考虑单一粒度的文本修改策略,如词级别或句级别,这并不足以详尽地探索文本空间以生成有效地对抗样本;2、攻击模型完成一次成功的攻击往往需要查询受害模型(victim model)成百上千次,而这在实际应用中是非常低效的。在这篇论文中,我们提出了MAYA(Multi-grAnularitY Attacking model )模型来高效地生成高质量的对抗样本,并且只需要对受害模型进行少量的查询。在此基础上,我们提出了基于强化学习方法中的行为克隆(behavior cloning)来训练一个多粒度攻击模型,通过学习MAYA算法的专家知识(expert knowledge),更进一步地减少了查询模型的次数。同时,我们成功地将该模型应用到只输出标签的黑盒模型上。我们进行了详尽的实验,结果表明我们的方法几乎在三个数据集三个受害模型上都有最好的表现,同时显著降低了受害模型的查询次数。
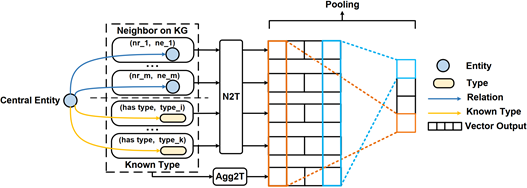
2. Context-aware Entity Typing in Knowledge Graph,Weiran Pan, Wei Wei*, Xian-Ling Mao,In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Findings of EMNLP'2021), Punta Cana, Dominican Republic.
内容简介:知识图谱实体类型推断(Knowledge Graph Entity Typing)旨在推断知识图谱中实体的缺失类型,是知识图谱补全(Knowledge Graph Completion)的一项重要子任务。挖掘同一实体的不同类型信息有助于构建包含丰富语义知识的知识图谱,具有重要的学术研究与商业应用价值。然而,这一问题并没有得到很好的解决,现有方法主要存在两点不足:1、现有方法通常只使用一个向量表示来代表一个实体,不但缺乏对同一实体不同语义方面的细粒度建模,还容易在推断过程中引入噪音信息;2、部分方法在推断实体缺失类型时忽略了实体的已知类型,未能全面利用实体的已知语义信息。在这篇论文中,我们提出了一种新颖的知识图谱实体类型推断方法,其主要包含如下两种推断机制:1、独立使用知识图谱上单个实体各个邻居进行推断;2、聚合知识图谱上单个实体所有邻居进行推断。通过独立使用邻居,模型能单独考虑实体的各个语义方面,有效降低无关信息对类型推断的干扰;聚合邻居则能同时捕捉实体的多个语义方面,有助于推断复杂类型。同时,模型将实体已知类型也视为实体邻居,进而利用它们推断实体缺失类型。为有效结合两种推断机制,本文设计了一种指数加权池化方法。此外,本文设计了一种新颖的损失函数能够有效缓解训练中的假阴性(false negative)错误问题。在真实知识图谱上的实验证明,我们的模型在MRR,MR以及Hit@1/3/10指标上超越了现有SOTA模型,且类型推断结果具有一定可解释性。