
CCIIP实验室2020级研究生刘宇航同学(2020年9月加入实验室,导师:魏巍)论文“Declaration-based Prompt Tuning for Visual Question Answering”及2021级研究生潘为燃同学(2021年9月入学,导师:魏巍)论文“Automatic Noisy Label Correction for Fine-Grained Entity Typing”被人工智能顶级国际会议IJCAI 2022 (Proceedings of the 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence)作为长文全文录用。2022届国际人工智能大会(IJCAI 2022)计划于2022年7月23日-7月29日在澳大利亚Messe Wien, Vienna会议中心召开。IJCAI是是中国计算机学会CCF推荐的A类国际学术会议,在人工智能领域享有较高学术声誉。这次会议共收到4535篇长文投稿,录用率仅为15%。
1. Declaration-based Prompt Tuning for Visual Question Answering,Yuhang Liu, Wei Wei*,Daowan Peng, Feida Zhu, In: Proceedings of the 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence (IJCAI-ECAI' 2022), Messe Wien, Vienna, Austria.
内容简介:目前,pre-training-then-fine-tuning范式在跨模态任务上取得了很大的成功,如视觉问答(Visual Question Answering)任务。其中,视觉语言模型(Vision-language models)首先通过自监督任务进行优化,例如掩码语言模型(Masked Language Model, MLM)和图文匹配任务(Image-text Matching, ITM),然后,在下游任务上使用全新的目标函数去优化模型,例如VQA任务中的答案分类。然而,这种模式存在上下游任务目标不一致的问题,从而限制预训练的VL模型对下游任务的泛化能力,而且还需要大量的标注数据进行微调。为了缓解这些问题,我们提出了一种用于视觉问答任务的VL微调新范式,即Declaration-base Prompt Tuning(DPT),其使用与预训练阶段相同的目标来适应到下游任务。具体来说,DPT采用Textual Adaptation来将给定问题转化为陈述句来作为提示模板(Prompt Template),并将答案分类问题转化为填词和图文匹配问题,从而将下游任务目标转换成了预训练阶段的目标形式。在多个数据集上的实验结果表明,在全监督/零样本/小样本场景下,DPT的准确率明显优于现有基线模型。
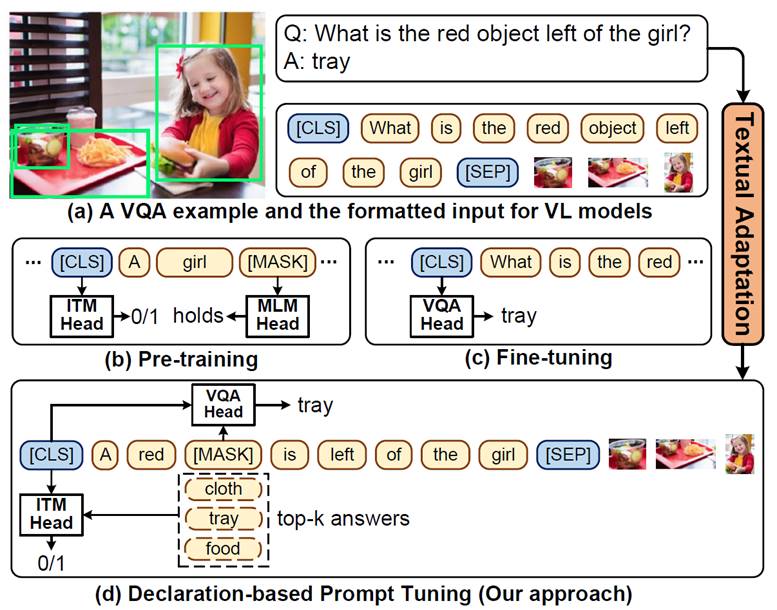
图1:现有pre-training-then-fine-tuning方法与DPT方法对比
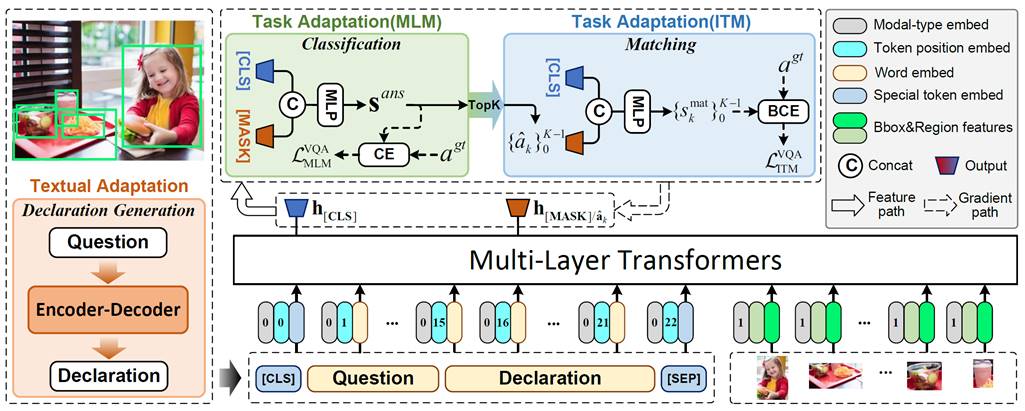
图2:DPT整体框架图
2. Automatic Noisy Label Correction for Fine-Grained Entity Typing,Weiran Pan, Wei Wei*,Feida Zhu, In: Proceedings of the 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence (IJCAI-ECAI' 2022), Messe Wien, Vienna, Austria.
内容简介:现有细粒度实体分类(Fine-grained entity typing, FET)方法主要基于大规模弱监督数据训练,但通常忽略了数据集中的噪声标签问题,从而严重影响模型性能。以往研究虽然在自FET 数据上自动去噪方面取得巨大进展,但其通常严重依赖于人工给定的先验知识(如预定义的分层类型结构、人工标注数据集等),因此,我们提出了一种无监督的模型训练方式,在不引入外部先验信息基础上实现自动修正FET 噪声标签,主要思想是考虑在模型过拟合前输出logits 估计标签概率(正或负),以过滤潜在噪声标签,从而利用剩余干净标签训练模型以重识别噪声标签。通过在两个基准数据集上的实验证明验证了所提模型的有效性。
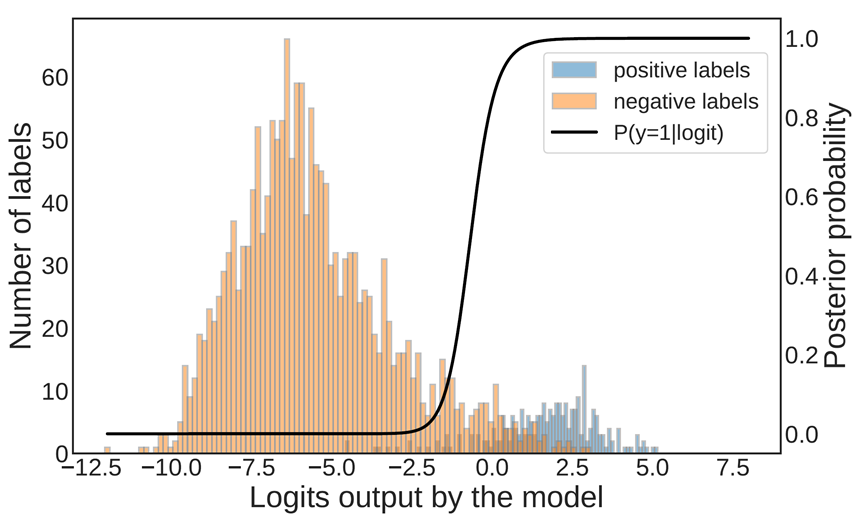
图1 模型在早停时在类型“organization”上logits输出以及算法估计的标签为正的后验概率P(y=1|logit)

图2 降噪结果示意,红色为假阳性标签,黄色为假阴性标签