CCIIP实验室“2023级研究生丁卓君、佟泽良、彭献书和25级研究生余曾祺,以及23级博士生瞿晓烨”(导师:魏巍)4篇论文被国际自然语言处理顶会(ACL 2025)长文全文录用。2025年国际自然语言处理会议ACL计划于2025年7月27日-8月1日在奥地利维也纳召开。ACL是中国计算机学会CCF推荐的A类国际学术会议,在人工智能及自然语言处理领域享有较高学术声誉。

1. 论文标题:Selecting and Merging: Towards Adaptable and Scalable Named Entity Recognition with Large Language Models (ACL 2025)
作者:Zhuojun Ding, Wei Wei*, Chenghao Fan
内容简介:对于基于大语言模型微调提升模型命名实体识别能力的范式而言,通常做法是利用多个领域(源域)的开源数据集/蒸馏数据集进行指令微调,此类方法通常能够在一定程度上提升模型泛化性(尤其是在未知领域)。然而,对于给定的目标域来说,上述源域数据可能对其无用甚至有害,导致模型微调只能得到次优解,同时模型可扩展性也受限。因此,提出基于模型选择-融合框架,具体地说为不同源域数据分别训练模型,通过领域相似度度量和数据采样两种不同评估策略方式选择适配目标域的源域模型。同时,为了充分利用不同源域知识,进一步利用模型参数融合方式构建适配目标域的任务混合模型。相比于传统混合所有源域数据的训练方式,所提方法几乎不引入额外计算开销,但可以针对不同目标域构建合适模型以提升模型在目标域上的泛化性。同时,可根据需求添加任意新模型或移除过时(或含大量噪声)的源域模型,有效提升了其可扩展性。通过在多个不同目标域数据集上的实验结果表明,所提方法取得了更好地泛化性能。进一步分析发现,源域模型数量敏感性及融合策略、在多个不同场景下等因素对模型性能影响,充分验证了所提方法的有效性。
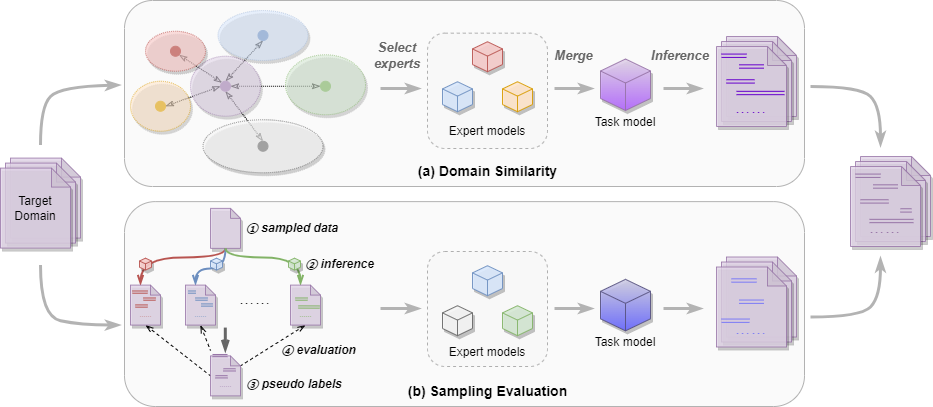
图1:模型框架图
2. 论文标题:GRAT: Guiding Retrieval-Augmented Reasoning through Process Rewards Tree Search (ACL 2025)
作者:Xianshu Peng, Wei Wei*
论文内容:如何有效提升大型模型在复杂多跳问答任务中的表现,已成为大模型检索增强生成(Retrieval-Augmented Generation, RAG)领域的研究重点。目前,现有方法通常是利用大型模型模拟人类思维过程,通过逐步执行检索增强生成。然而,此类方法一般只能进行单链式推理,缺乏多推理路径探索能力,导致模型在逐步评估生成过程中无法取得全局最优性能。同时,上述方法在分解复杂问题过程中,严重依赖于中间标注结果作为监督信号,而上述标注需要耗费大量人力成本。因此,提出了 GRAT,一种由蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)和过程奖励机制共同指导的复杂多跳问题回答方法。具体来说,GRAT具有自我评估与自我纠错能力,能够为搜索路径中每个中间步骤分配合适的细粒度奖励而无需额外人工标注,该细粒度标注可用于模型自训练以持续更新GRAT问题分析与推理能力。通过在多跳问答数据集(比如HotPotQA、2WikiMultiHopQA、MuSiQue 和 Bamboogle)上实验结果表明,GRAT在多个任务中均优于现有多个基于RAG的基线模型,同时引入自训练机制后,GRAT的推理性能可得到进一步提升。
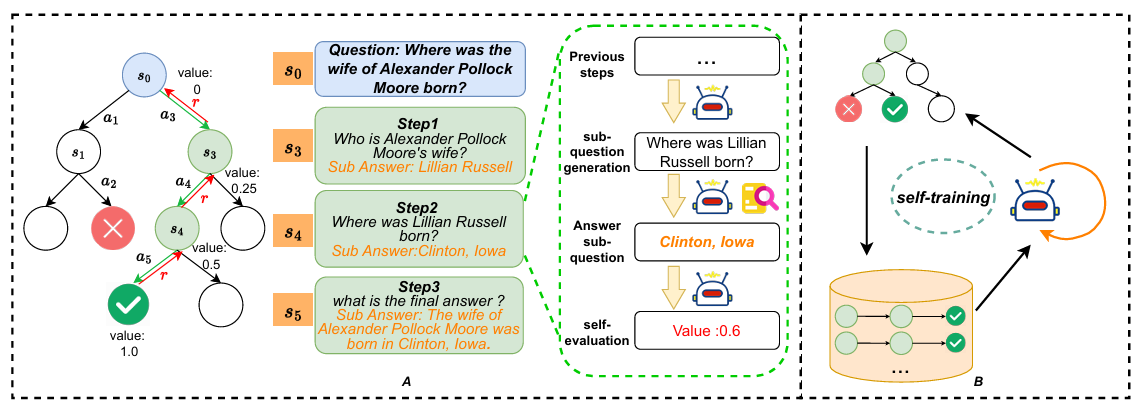
图2: GRAT模型架构图
3. 论文标题:Multi-level Association Refinement Network for Dialogue Aspect-based Sentiment Quadruple Analysis (ACL 2025)
作者:Zeliang Tong, Wei Wei*, Xiaoye Qu, Rikui Huang, Zhixin Chen, Xingyu Yan
内容简介:本研究聚焦于对话情感四元组抽取(Dialogue Aspect-based Sentiment Quadruple, DiaASQ)任务,旨在从对话中识别出目标、方面、观点及情感等四元组信息。该任务挑战性在于要抽取的四元组不同元素可能分布在历史多轮对话中,区别于传统方面级情感识别任务。因此,如何构建情感词与不同对话之间情感关联是本任务的核心挑战之一。现有方法多依赖预定义的对话结构和浅层词语语义,难以捕捉深层次的情感关联性。因此,提出了一种多层级关联优化网络(MARN),其通过整体语义建模强化对话间的情感关联。同时,设计了新颖的跨话语句法解析器(CU-Parser),以提升词语间的结构关联建模能力。此外,针对标注数据稀缺问题,还引入了基于大语言模型(Large Language Model, LLM)的多视角数据增强策略,通过多任务学习范式以增强模型在低资源场景下的性能。实验结果表明,MARN在多个评估指标上均取得了当前最优性能,且在低资源条件下表现出较强的鲁棒性。
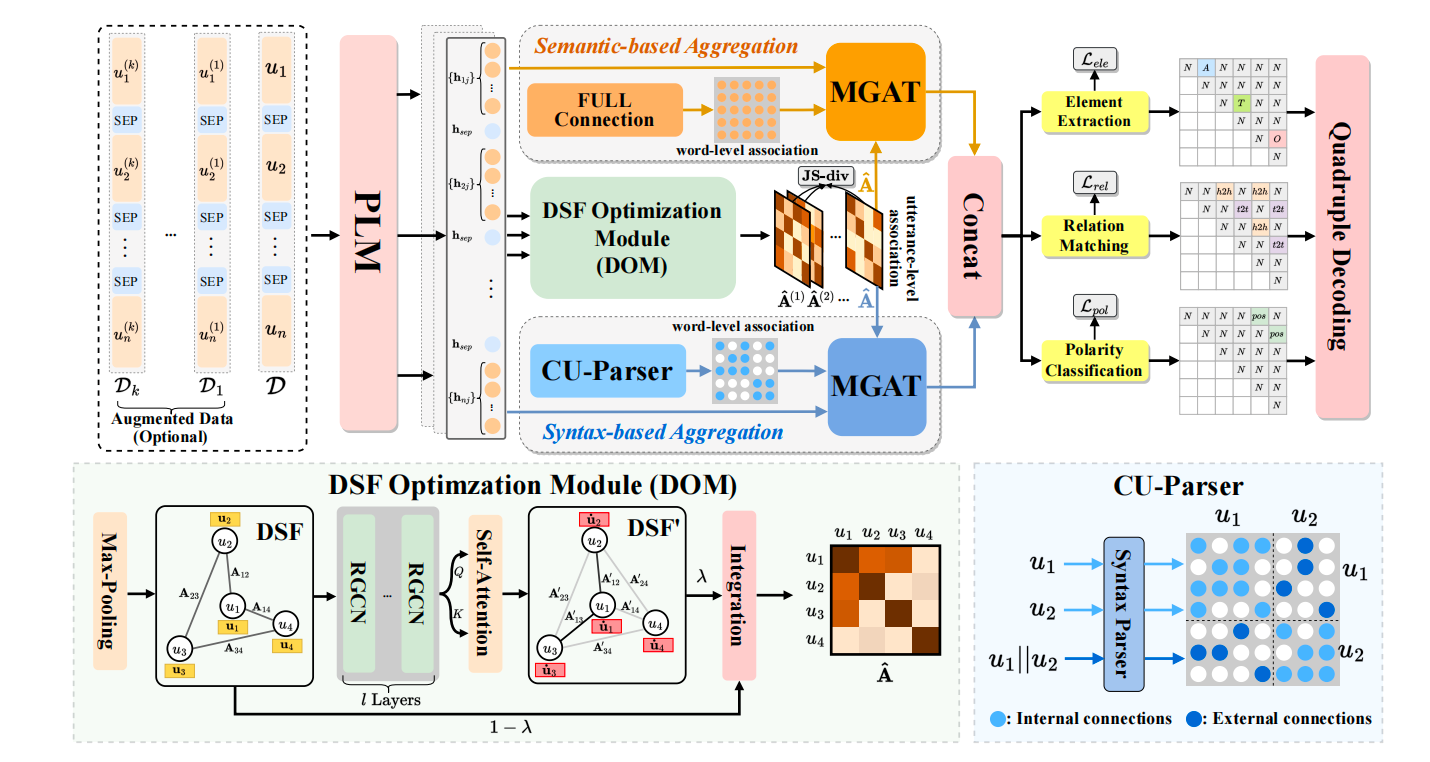
图3:MARN模型框架图
4. 论文标题:Cooperative or Competitive? Understanding the Interaction between Attention Heads From A Game Theory Perspective(ACL 2025)
作者:Xiaoye Qu#, Zengqi Yu#, Dongrui Liu, Wei Wei*, Daizong Liu, Jianfeng Dong, Yu Cheng
内容介绍:近年来,大语言模型(LLMs)在自然语言处理领域取得了显著进展,而注意力机制作为其核心组件之一,在提升模型语义建模能力方面发挥了关键作用。然而,当前关于注意力头之间协作与竞争关系的研究仍显不足。多数现有研究仅关注单个注意力头作用,忽略了多个不同注意力头在推理过程中可能存在交互效应。为深入剖析这一“黑箱”机制,首次引入合作博弈论视角,借助哈萨尼股息(Harsanyi Dividend)对注意力头间的协同与冲突关系进行量化分析,揭示了仅少数注意力头组合具有显著的协作增益,而大多数组合贡献有限,甚至存在隐性竞争。为缓解注意力头之间的无效交互,提出了一种训练无关的博弈论注意力校准方法(Game-theoretic Attention Calibration, GAC)。GAC首先识别出在哈萨尼分析中表现出正向协同效应的“显著组”,并保留上述注意力头。同时,针对存在竞争关系的其余注意力头,GAC对其注意力分布进行精细调节,通过平滑过度集中的注意力权重,提升整体注意力协作收益。在不额外增加训练模型参数的前提下,GAC优化了注意力机制的内部结构。实验结果表明,GAC在17个基准任务(涵盖文本分类、多选问答及开放式问答等多种不同任务类型)上的表现显著优于现有无训练调整方法,表明其适用于多种模型结构与规模。此外,GAC在多模态大模型(MLLM)上同样展现出良好的泛化能力,验证了其跨模态与跨任务的优越性。上述发现不仅为优化注意力机制提供了新的研究思路,也为深入理解大模型的推理过程提供了理论支撑。
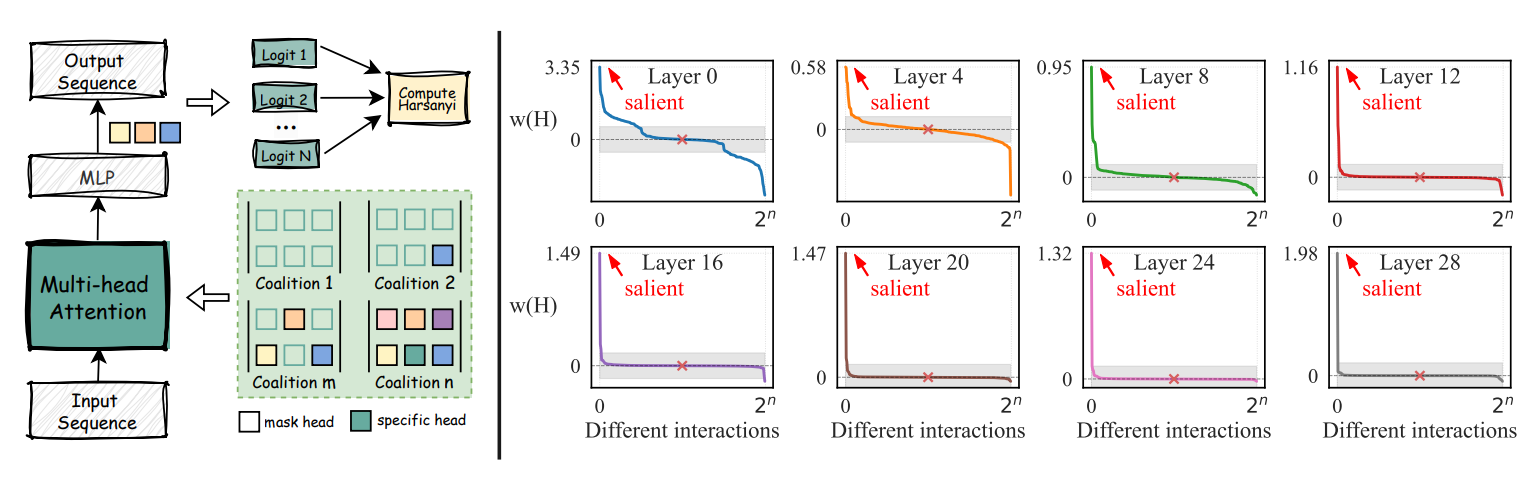
图4:GAC模型框架图