CCIIP实验室研究生“范城豪、鲁镇仪、刘思辰及博士生瞿晓烨”(导师:魏巍)的论文 “Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment”被机器学习顶级会议ICML 2025录用。第42届机器学习年会(ICML 2025)计划于2025年7月13日-7月19日在加拿大温哥华召开。ICML是中国计算机学会CCF推荐的A类国际学术会议,在机器学习领域享有较高学术声誉。这次会议共收到破纪录的12,107篇有效投稿,录用3,260篇,录用率26.9%。
论文标题:Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment(ICML 2025)
论文作者:Chenghao Fan, Zhenyi Lu, Sichen Liu, Xiaoye Qu, Chengfeng Gu, Wei Wei*, Yu Cheng
内容介绍:在大模型时代,高效微调技术成为突破训练瓶颈的关键,然而传统低秩适应(LoRA)方法虽降低了参数规模,却难以媲美全量微调(Full FT)的性能,且面临初始化次优与梯度未对齐的挑战。针对这一问题,华中科技大学(认知计算与智能信息处理实验室,CCIIP)与香港中文大学联合团队提出全新框架GOAT(Great LoRA Mixture-of-Expert),通过自适应奇异值分解(SVD)与专家混合(MoE)优化对齐机制,显著提升LoRA的性能,在多个任务中逼近甚至超越全量微调效果,为高效大模型适配开辟新路径。
现有LoRA方法多依赖静态奇异值初始化或简单零初始化,导致预训练知识利用不充分,且MoE架构中专家权重与梯度动态复杂,加剧优化难度。GOAT创新性地提出两大核心设计:(1)自适应SVD-MoE初始化:将预训练权重分解为多组奇异值片段,通过动态路由机制自适应选择与任务相关片段初始化专家,以便充分挖掘预训练知识;(2)理论驱动的梯度对齐策略:基于等效权重与梯度理论分析,推导最优缩放因子与权重对齐方案,使低秩更新梯度逼近全量微调,大幅提升收敛速度与性能。实验表明,仅需调整缩放因子,无需修改架构或算法,即可实现高效优化。
为验证方法有效性,GOAT在25个跨领域基准任务中展开评测,涵盖自然语言理解(GLUE)、常识推理(Commonsense170K)、图像分类(ImageNet系列)及自然语言生成(对话,数学,代码等问题)。实验结果显示,GOAT在单LoRA与LoRA-MoE方法中均达到SOTA性能,并在多个任务上超过全量微调性能。此外,GOAT在域外泛化(OOD)任务中表现稳健,如在未参与训练的代码生成任务HumanEval上准确率达25.61%,优于同类方法3.14%。
值得关注的是,GOAT在计算效率上优势显著:相比全量微调MoE,其训练内存降低98%(34.85GB vs. 640GB),耗时缩减65%(37小时 vs. 106小时),且支持动态扩展专家数量与激活比例,在32总秩下,8专家配置即可平衡性能与存储开销。
该成果已发表于顶级学术会议ICML,代码即将开源。GOAT通过理论创新与工程优化,为大模型高效适配提供了可扩展、低成本的解决方案,有望推动AI技术在 NLP、多模态等领域的快速落地,助力工业界实现绿色高效的模型迭代。
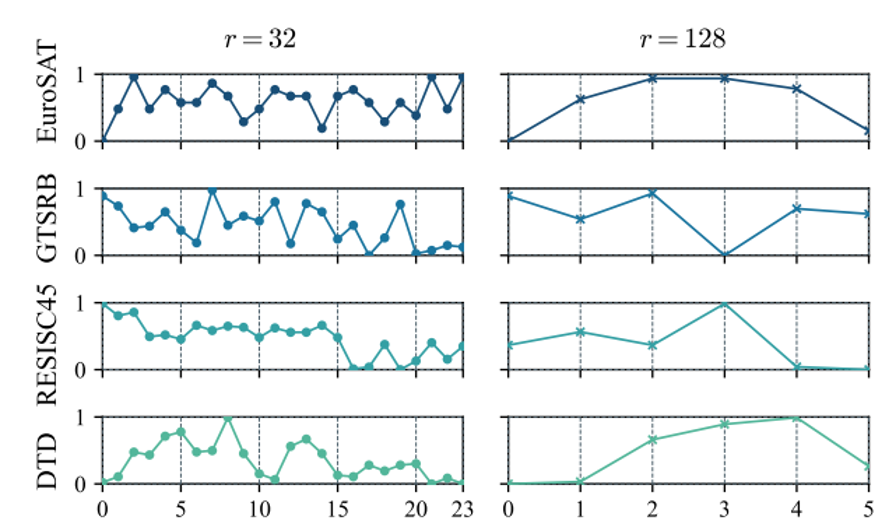
图1:不同SVD片段初始化对不同大小秩(32 vs. 128)的影响(性能通过最小-最大缩放归一化)

图2:模型架构图