
CCIIP实验室22级研究生田杰及23级博士生瞿晓烨(导师:魏巍)的论文 “Extrapolating and Decoupling Image-to-Video Generation Models: Motion Modeling is Easier Than You Think”被计算机视觉顶级会议CVPR 2025高分录用(4,4,4,5)。本次CVPR 2025会议共有13,008篇投稿,录用2,878篇,录用率22.1%。相较于去年,CVPR 2025总投稿数再次增加,而录用率却降低1.5%。
论文标题:Extrapolating and Decoupling Image-to-Video Generation Models: Motion Modeling is Easier Than You Think(CVPR 2025)
论文作者:Jie Tian, Xiaoye Qu, Zhenyi Lu, Wei Wei*, Sichen Liu, Yu Cheng
内容介绍:在图像生成视频任务(Image-to-Video Generation, I2V)中,通常需要根据给定的静态图像和条件(如文本描述)生成逻辑连贯的视频序列,其核心挑战之一在于如何保证生成视频内容中目标的外观一致性,且确保生成视频内容的语义一致性及逻辑连贯性,比如运动的流畅性。然而,现有I2V扩散模型(I2V-DMs)普遍存在两类典型问题:(1) 生成的视频序列受限于运动幅度;及(2)图像条件与文本条件间容易产生冲突,导致文本指令失效,即当模型过度依赖图像信息时,而往往很难有效遵循给定的复杂指令生成视频序列。针对上述问题,本文提出了一种创新的"外推-解耦"框架,旨在有效缓解I2V任务中的图像依赖问题,该框架采用多阶段处理策略,主要包含三个独立处理阶段:
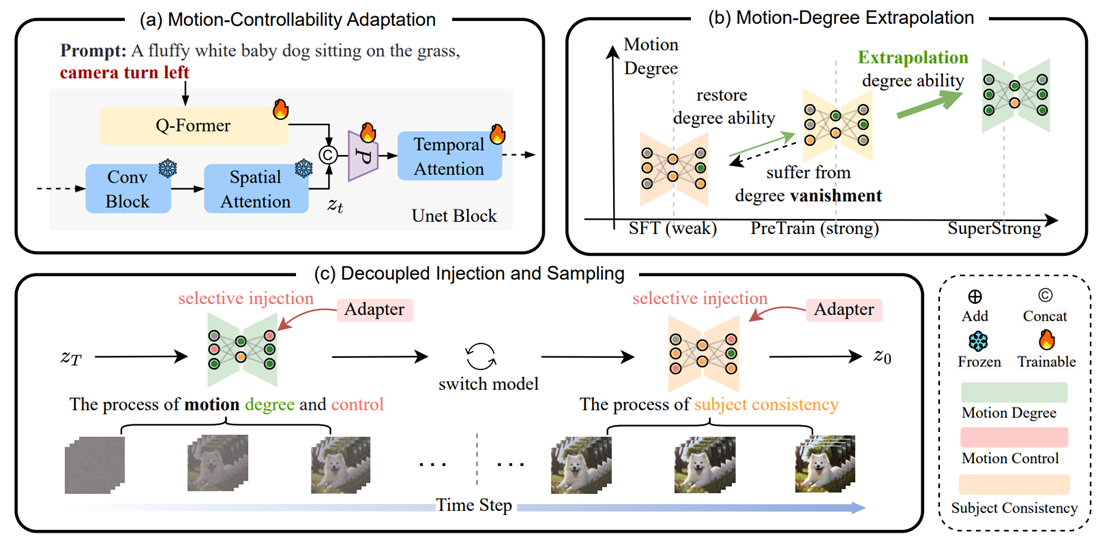
图1:外推-解耦视频生成框架
(1)在I2V-DM模型的基础上,利用轻量级、可学习的适配器将文本条件注入时间模块中微调,以提高运动可控性(如图1-(a)部分);
(2)引入无训练外推策略扩大运动的动态范围,有效反转微调过程以显著增强运动幅度(如图1-(b)部分);
(3)解耦不同运动能力相关参数,并将其更新到基础I2V-DM模型中,以便于I2V-DM在不同去噪时间步长下处理不同程度的运动可控性和动态性,并根据时间动态调整与运动相关参数(如图1-(c)部分)。
通过在最新的视频生成榜单VBench上的实验结果显示,所提模型较基于图像I2V的常规模型(如Animate-Anything,SVD和DynamicicCrafter)在Motion Degree 和Motion Control性能指标上有大幅提升(20.67%和12.76%), 同时能够保证生成视频的语义一致性和质量不受任何影响,甚至有略有提升。
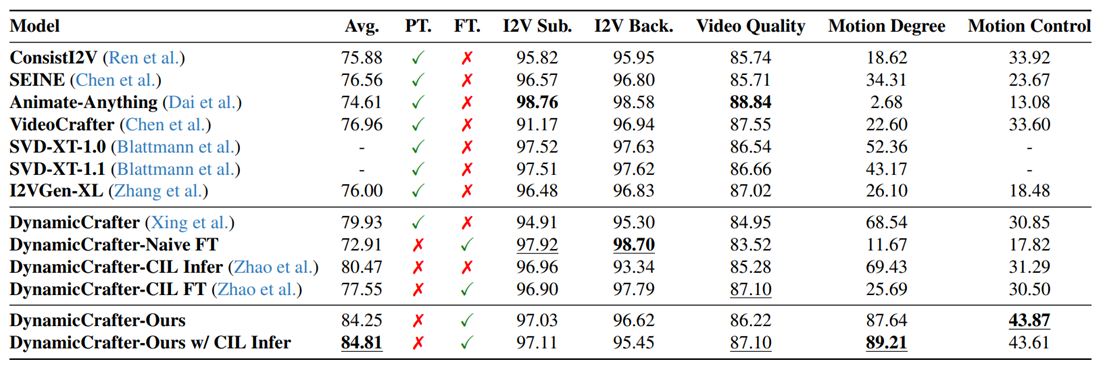
图二 Vbench-I2V基准实验结果