
CCIIP实验室22级研究生熊添恒同学(导师:魏巍)的论文 “Span Aware Detection Transformer for Moment Retrieval”,22级研究生张湘敏同学(导师:魏巍)的论文 “Modal Feature Optimization Network with Prompt for Multimodal Sentiment Analysis”;23级研究生佟泽良、丁卓君同学(导师:魏巍)的论文 “EvoPrompt: Evolving Prompts for Enhanced Zero-Shot Named Entity Recognition with Large Language Models”;以及24级研究生陈宇轩同学(导师:魏巍)的论文 “CoMIF: Modeling of Complex Multiple Interaction Factors for Conversation Generation” 被国际自然语言处理顶会(COLING 2025)长文全文录用。2025年国际自然语言处理会议(COLING 2025)计划于2025年1月19日-1月24日在阿联酋阿布扎比召开。COLING是中国计算机学会CCF推荐的B类国际学术会议,在人工智能及自然语言处理领域享有较高学术声誉。
1. 论文标题:Span Aware Detection Transformer for Moment Retrieval
作者:Tianheng Xiong, Wei Wei*, Kaihe Xu, Dangyang Chen
内容简介:当前基于Detection Transformer的自然语言视频定位(Moment Retrieval)方法主要遵循基于模态融合(Modal Fusion)的编码器+基于查询修正(Query Refine)的解码器范式,然而在查询修正过程中通常存在以下两个问题: 1)利用可学习参数初始化Query(由span anchor和content embedding两部分组成),而忽略了Query与视频-文本实例对的强相关性,导致初始Query缺乏实例信息;2)没有充分利用span anchor在查询修正过程中的引导作用,忽略了span anchor在自然语言视频定位任务中与帧特征的对应关系,导致模型缺乏对片段的精确感知。为了解决上述问题,我们提出了Span Aware DEtection Transformer,使用实例融合特征初始化Query来增强实例信息,同时设计了片段感知解码器来充分发掘span anchor的直接引导作用,此外在模型中我们探究了不同粒度的模态融合方法,以及基于去噪学习的解码器增强方法以提升模型对片段的感知能力。实验结果表明,SA-DETR在QVHighlights,Charades-STA和TACoS三个数据集上取得了先进性能。
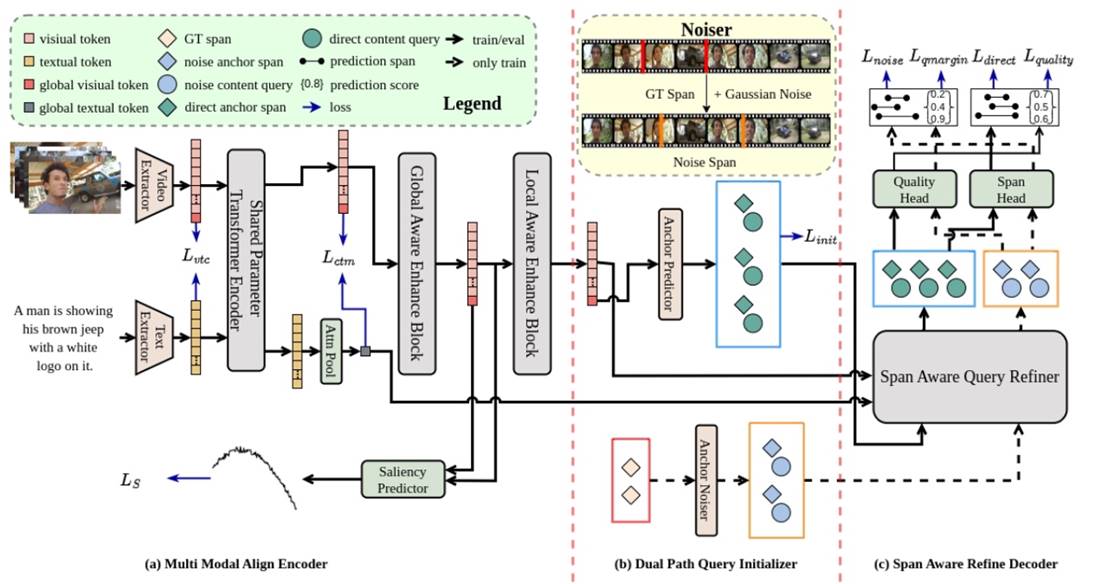
图1. SA-DETR整体框架图
2. 论文标题:Modal Feature Optimization Network with Prompt for Multimodal Sentiment Analysis
作者:Xiangmin Zhang, Wei Wei*, Shihao Zou
内容简介: 多模态情感分析(MSA)主要是通过分析多模态数据来理解人类情感状态。然而,不同模态通常携带的有效信息具有不平衡性,传统方法通常没有充分挖掘模态间的互补性导致性能不佳。因此,为了充分挖掘模态中有效信息,解决欠优化的模态表示问题,我们提出一种新的基于模态提示注意机制的模态特征优化网络(MFON)。具体来说,首先利用 Transformer架构(K,Q,V)分别学习不同模态数据基于文本模态的注意力分布(在MSA任务中文本模态数据为backbone信息),以增强不同模态中情感相关信息的表示,随后通过最小化对比损失以更好地提取跨模态的相关特征,同时利用蒸馏策略实现模态内的数据增强,最终通过聚合模块实现多模态数据融合以完成多模态情感分析任务。在公共基准数据集上的广泛实验结果表明提出的方法优于现有的最先进模型。
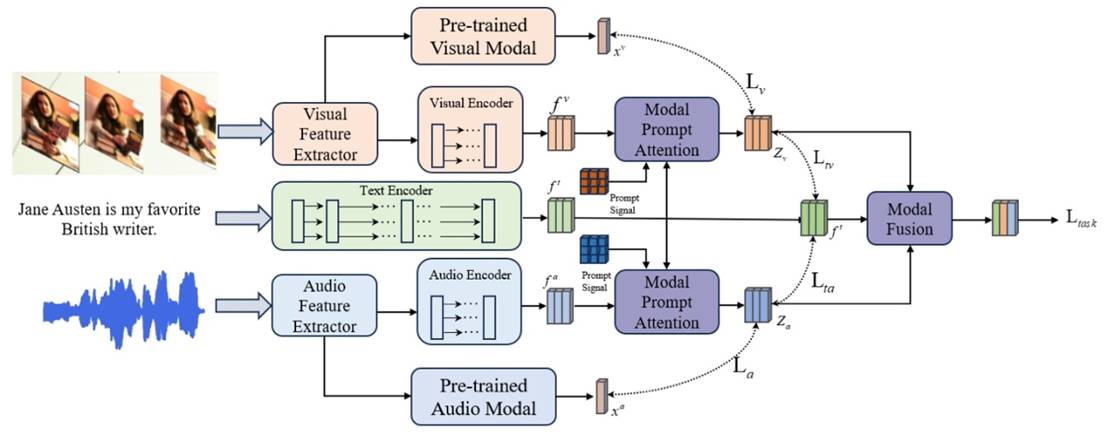
图2. MFON整体框架图
3. 论文标题:EvoPrompt: Evolving Prompts for Enhanced Zero-Shot Named Entity
Recognition with Large Language Models
作者:Zeliang Tong#, Zhuojun Ding#, Wei Wei*
内容简介: 针对零样本命名实体识别问题,重点探索在无标注数据条件下,利用大语言模型(LLMs)的推理能力从文本中识别预定义实体。目前,已有基于上下文学习(ICL)的低资源方法性能显著,但其在实体类型理解以及混淆类型区分方面存在不足,且严重依赖于大量人工标注示例或人工设计标准,导致其在低资源场景下性能不佳,尤其是在类间相似性高易混淆类别上性能不佳。为应对上述挑战,我们提出一种“演进式提示”(Evolving Prompts)框架,通过基于大模型的伪标签样本及类型释义提升模型对实体类型的理解以及混淆类型间的可区分性,从而有效提升ICL质量,并利用迭代优化提升模型性能。具体而言,框架首先生成伪标签并:(1)给出不同实体类型定义说明;及(2)生成语义混淆类型间区分性解释说明。随后,利用生成伪标签构建ICL示例,用于迭代输入从而持续改进模型性能。另外,为提升伪标签可靠性及多样性,设计了一种结合自洽性和元学习的样本选择策略,通过筛选预测一致性样本降低噪声干扰,同时利用元学习框架生成具有代表性的元聚类中心样本,用于避免负优化问题并逐步提升伪样本标签质量。因此,该框架不依赖人工标注从而大幅降低标注成本,同时通过迭代优化框架提升ICL示例质量,并降低易混淆样本间干扰。实验表明,该方法显著提升了零样本NER性能,为低资源场景下LLMs应用提供了新的思路。
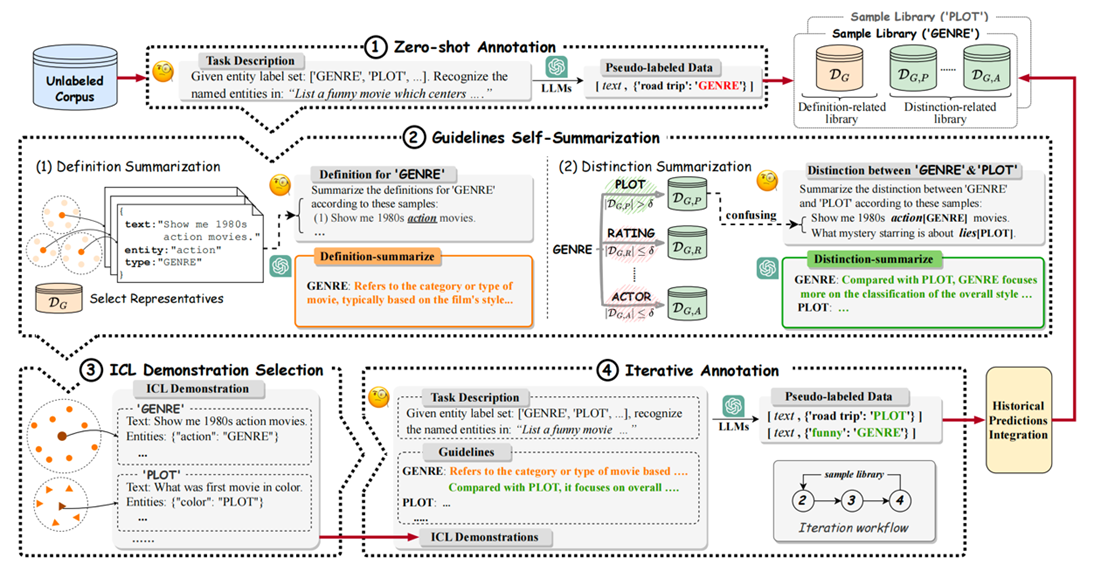
图3. EvoPrompt整体框架图
4. 论文标题: CoMIF: Modeling of Complex Multiple Interaction Factors for Conversation Generation
作者:Yuxuan Chen, Wei Wei*, Shixuan Fan, Kaihe Xu, Dangyang Chen
内容简介:开放域对话任务中生成拟人化回复是其重要任务之一,其通常涉及情感、个性、话题多种复杂因素影响,已有生成方法取得了显著进展,比如在共情、个性化和语义一致性等方面。但以往工作通常仅限于对单一因素建模,而忽略了不同因素间隐式关联关系,导致生成回复的性能不佳。另一方面在解码中,token-level生成时会受到不同因素影响,因此仅在sentence-level上考虑多种因素影响也很难生成高质量回复。针对上述问题,我们提出了一种通用回复生成框架(CoMIF),其能够同时建模多种复杂人机交互因素,从而生成更拟人化的回复。为了建模因素间隐式关联,CoMIF首先采用动态感知模块构建一个有向协作图,用于联合学习每个因素随时间变化的动态性及其交叉依赖关系。此外,我们设计了一个可扩展的自适应模块,在token级引入因素信号以生成更符合人类特征的多因素回复。在多个数据集上的广泛实验表明,与现有最先进方法相比,该方法在生成回复的拟人化特征方面,尤其是在多因素建模方面表现出色。
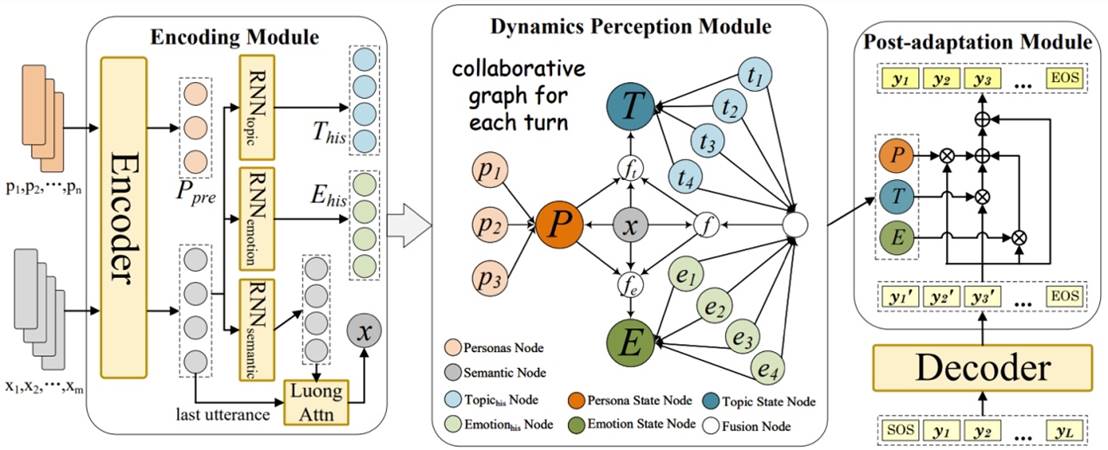
图4. CoMIF: 整体框架图
5. 论文标题:Look, Compare, Decide: Alleviating Hallucination in Large Vision-Language Models via Multi-View Multi-Path Reasoning
论文作者:Xiaoye Qu, Jiashuo Sun, Wei Wei*, Daizong Liu, Jianfeng Dong and Yu Cheng
内容简介:近期大型视觉语言模型(LVLMs)在多模态上下文理解方面表现出令人印象深刻的能力。然而幻觉问题始终存在,即生成与图像内容不一致的输出。为了缓解幻觉,之前的研究主要集中在使用自定义数据集重新训练LVLMs。虽然有效,但本质上会带来额外计算成本。在本文中,我们提出了一种无训练框架Multi-View Multi-Path Reasoning(MVP),旨在通过多视图多路径推理最大化LVLMs的固有能力,从而减少幻觉。具体而言,我们首先设计了一种多视图信息获取策略,以全面感知图像中的综合信息,其丰富了LVLMs中原始视觉编码器捕获的全局信息。此外,在答案解码过程中,我们为每个信息视图提出了多路径推理,以量化和聚合在多个解码路径中每个潜在答案的确定性得分,最终决定输出答案。通过充分掌握图像中的信息,并在解码时仔细考虑潜在答案的确定性,我们的MVP可以有效减少LVLMs中的幻觉问题。大量实验验证了我们提出的MVP在四个知名LVLMs中显著缓解了幻觉问题。
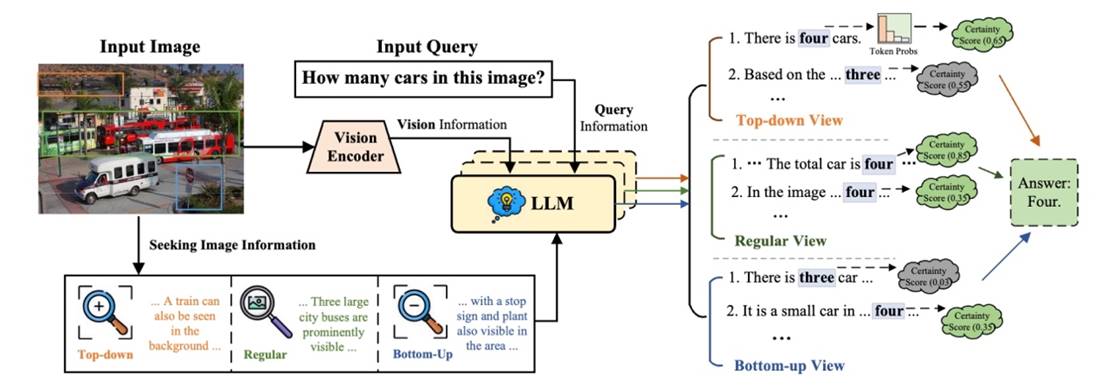
图5. MVP整体框架图