CCIIP实验室2022级研究生鲁镇仪同学(导师:魏巍)的论文“Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging”以及23级研究生范城豪同学(导师:魏巍)的论文“On Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion”被计算理论国际顶会(NeurIPS 2024)长文全文录用!2024年国际神经信息处理系统年度会议(NeurIPS 2024)计划于2024年12月9日-12月15日在加拿大温哥华召开。NeurIPS是中国计算机学会CCF推荐的A类国际学术会议,在人工智能及计算机理论领域享有较高学术声誉。
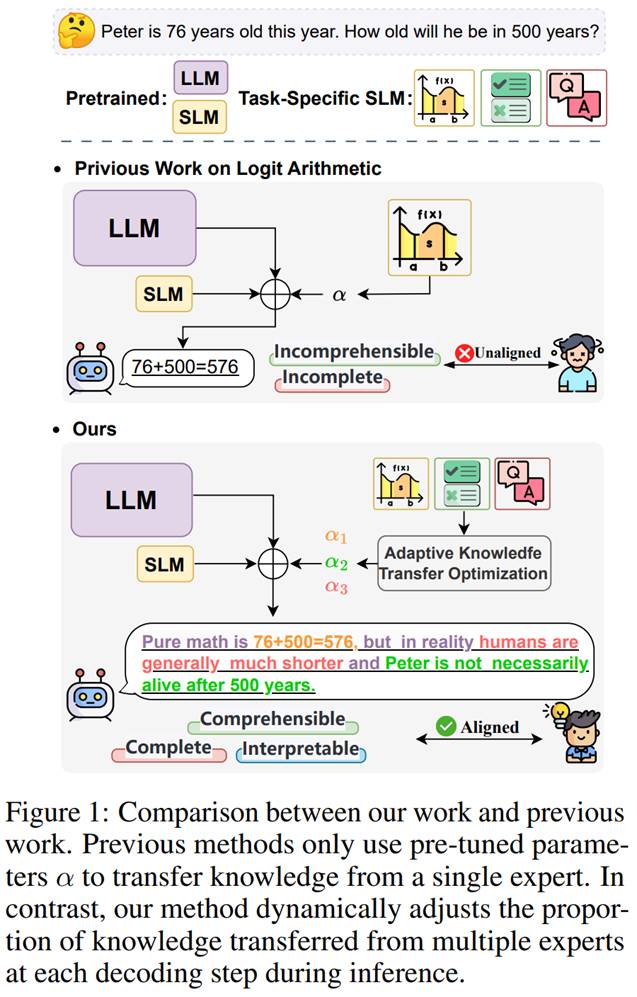
1. 论文标题:On Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion
作者: Chenghao Fan #, Zhenyi Lu #, Wei Wei *, Jie Tian, Xiaoye Qu, Dangyang Chen, Yu Cheng (#:共同一作,*:通讯作者)
内容简介:针对特定应用领域的大模型高效微调在工业界和学术界受到广泛关注,但受限于大模型庞杂的参数规模,使得大模型训练尤为困难。目前该领域已有众多有效的方法被提出,但梯度更新过程中的计算量仍然会显著增加显存开销,导致GPU资源紧张。因此,我们主要探索如何利用知识迁移范式,通过在一系列特定任务较弱的小模型上进行微调后将微调后的知识迁移到大模型上,而无需额外增加模型训练开销,从而大幅提升大模型的训练效率。在本文中,我们主要研究如何利用 logits 算术实现从(弱)小模型到(强)大模型的知识迁移,目前已有方法仅能针对静态知识通过计算转移比例方式实现小模型上的复杂知识迁移,但是容易导致次优化问题。因此,我们提出一种动态 logit 融合方法实现特定任务微调小模型上的实现知识迁移,主要思想是通过在每个解码步骤上实现自适应的模型权重分配,利用Kullback-Leibler 散度进行优化约束,对齐微调小模型上的知识与真实大模型上微调知识,即保证融合多个微调后的小模型的知识等价于直接在大模型上进行微调后的知识变化。通过在多个基准数据上实现显示,所提模型在单任务和多任务设置下均取得了SOTA性能。其中在将7B微调小模型的知识迁移到13B大模型实验中,所提方法在单任务场景下迁移后的大模型性能几乎等价于在大模型进行全量微调(性能比为0.964,最优比为1.0),在多任务场景下的性能比则为0.863,此外在OOD(域外泛化性,即训练集上未出现的任务)方面,也取得了显著的性能提升,同时我们也进一步证明了所提模型易于与上下文学习(In-Context Learning)和算术模型(Task Arithmetic)结合,从而应用于多任务场景中。


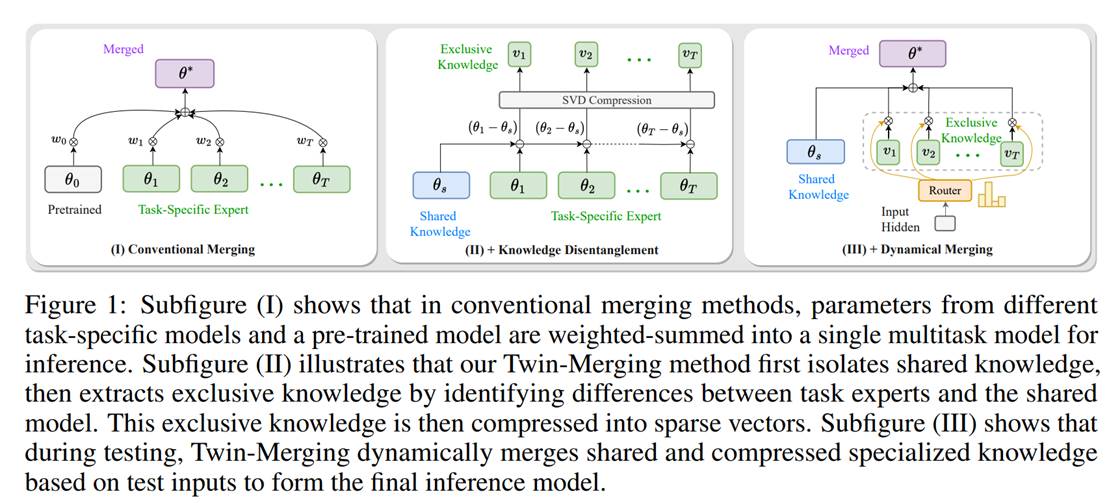
2. 文标题:Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
论文作者: Zhenyi Lu #, Chenghao Fan #, Wei Wei *, Xiaoye Qu, Dangyang Chen, Yu Cheng (#:共同一作,*:通讯作者)
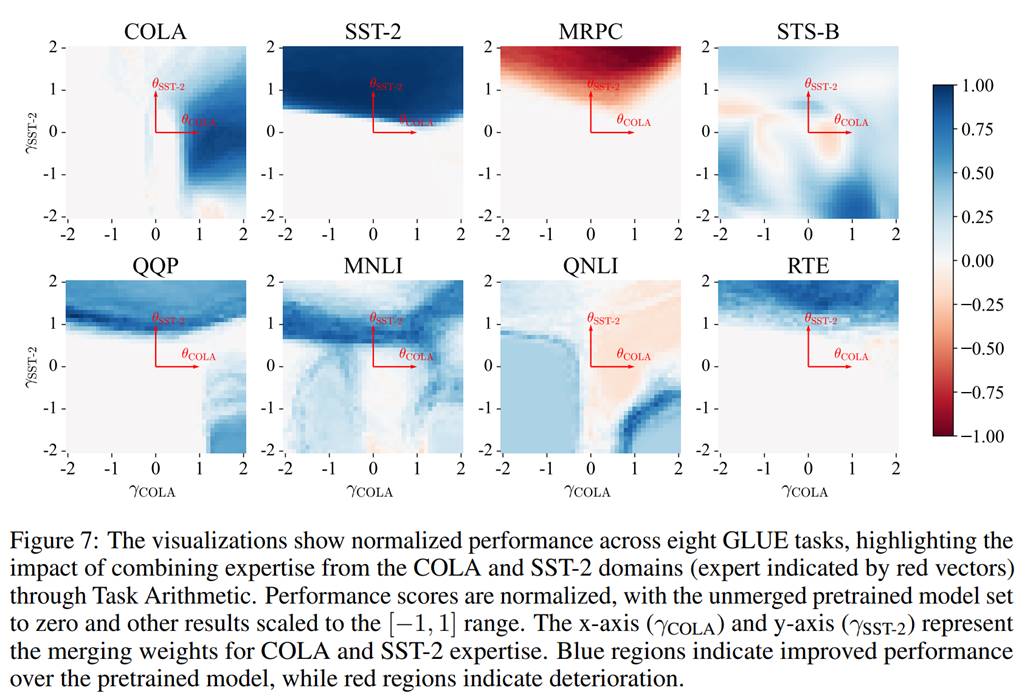
内容简介:在大语言模型时代,混合专家系统(Mixture-of-Experts,MOE,即多模型融合)是目前工业界和学术界普遍关注的问题,其能够在不增加额外训练开销情况下有效融合多个具有不同特异性的单个模型以完成复杂多任务需求。然而,传统模型融合方法忽略:(1)不同模型间差异性;(2)数据异质性,从而导致融合后模型性能与微调模型间性能存在显著差距,而通用模型则因缺乏对多样化数据的灵活性,而导致其性能下降。经研究发现,不同模型中存在共有知识和专有知识两部分,将其进行差异化合并对融合后的模型性能具有重要作用,而直接合并知识则会导致合并后模型整体性能下降。因此,我们提出了一种双融合(Twin-Merging)方法,其主要包含两个模块:(1)将知识模块化为共享和专有部分,并进行压缩以减少知识冗余并提升融合效率;(2)根据输入数据动态融合模型共享/专有(任务特异性)知识,利用上述模块能够有效缩小融合模型与全量微调模型间的性能差距,从而提升模型对异质性数据的适应性。通过在12个经典的判别/生成任务数据集上实验显示所提方法的有效性,尤其是在判别上的性能,其绝对归一化分数平均提升28.34%,而在生成任务上甚至超越了全量微调模型的性能上限。