
CCIIP实验室2022级博士生黄日葵同学(2022年9月入学,导师:魏巍)论文“Confidence is not Timeless: Modeling Temporal Validity for Rule-based Temporal Knowledge Graph Forecasting”,22级研究生范士轩同学(2022年9月入学,导师:魏巍)论文“Personalized Topic Selection Model for Topic-Grounded Dialogue”及鲁镇仪和田杰同学论文(2022年9月入学,导师:魏巍)“Mitigating Boundry Ambiguity and Inherent Bias for Text Classification in the Era of Large Language Models”被第62届自然语言处理领域顶级国际会议(ACL2024)分别作为main conference及findings长文全文录用。第62届国际计算语言大会(The 62nd Annual Meeting of the Association for Computational Linguistics)将于2024年8月11日-8月16日在泰国曼谷召开。ACL(Annual Meeting of the Association for Computational Linguistics)是计算语言学和自然语言处理领域的国际学术会议,由国际计算语言学协会组织,每年召开一次,在人工智能领域享有较高学术声誉,是中国计算机学会CCF推荐的A类国际学术会议。
(1)标题:Confidence is not Timeless: Modeling Temporal Validity for Rule-based Temporal Knowledge Graph Forecasting(ACL 2024)
论文作者:Rikui Huang, Wei Wei*, Xiaoye Qu, Shengzhe Zhang, Dangyang Chen, Yu Cheng
内容简介:目前时序知识图谱预测(TKGF)已成为作为知识图谱研究的一个重要分支,区别于传统基于神经网络模型的不可解释性,基于规则的方法因其高效性和可解释性而备受关注。但已有方法忽略了对规则时效性的建模,即不同规则的预测效力(置信度)会随着时间的推移而衰减(而非时间无关)。正确估计规则的时效性对提升预测结果的准确性至关重要,现有方法缺乏对置信度随时间的演化模式建模,而已有基于不准确的启发式规则的置信度估计方法将导致其存在性能瓶颈。针对上述问题,我们提出了一种基于规则时效性估计的时序知识图谱预测框架(TempValid)以对规则的时效性进行显示建模。具体来说,我们设计了一个随时间衰减的时间函数用来动态调整衰减率以度量规则的时效性,其中相关参数(置信系数/衰减系数)被定义为可学习的参数,以避免不准确的启发式估计和潜在的组合爆炸问题。同时,为了有效优化TempValid框架,我们还设计了“规则对抗负采样”和“时间感知负采样”策略以优化TempValid学习效果。在已有六个TKGF数据集上实验显示TempValid 较已有基于规则的SOTA基线模型具有更优性能,尤其是在跨领域和低资源场景下的规则学习任务中。

图1:不同规则置信度在不同时序模式下变化
(2)标题:Personalized Topic Selection Model for Topic-Grounded Dialogue (Findings of ACL 2024)
论文作者:Shixuan Fan, Wei Wei*, Xiaofei Wen, Xian-Ling Mao, Jixiong Chen, Dangyang Chen
内容简介:近年来,基于主题的对话(TGD)系统因其强大性能而备受关注,其能主动根据给定主题引动用户完成对话任务。通常,不同个性用户会选择不同主题生成回复,而已有基于全局主题选择的方法忽略了上述差异性,且没有考虑到预先给定的个性信息通常含有冗余噪声,只有部分与下一个生成的回复相关,从而导致预测主题与用户兴趣相关性不高,甚至上下文无关。针对上述问题,我们提出了一种基于主题引导的个性化对话主题选择模型(即PETD),其主要利用辅助信息间的隐式关联信息建模以提升主题预测准确性,从而有效提升用户参与性及对话连贯性。具体来说,我们通过度量全局主题与个性相关性,利用相关性高的全局主题扩展用户个性表示。同时,提出一种基于对比学习的个性选择器以抑制不相关个性对主题选择影响,即用于在缺乏相关个性注释的约束下过滤不相关个性信息影响。实验显示所提方法在不同评估指标上均优于SOTA基线方法,能够生成多样化的相关回复。

图2:PETD结构-不同颜色代表不同个性及其对应全局主题
(3)标题:Mitigating Boundary Ambiguity and Inherent Bias for Text Classification in the Era of Large Language Models (Findings of ACL 2024)
论文作者:Zhenyi Lu #, Jie Tian #, Wei Wei*, Xiaoye Qu, Yu Cheng, Wenfeng Xie, Dangyang Chen
内容简介:文本分类任务是自然语言处理领域基本任务之一,在真实场景下具有较高的实用性,但在大模型(LLMs)时代该任务并没有被很好的探究。经过研究发现,现有基于LLMs的分类方法对分类数量和类别顺序是敏感的,通过广泛实验分析发现其主要是由于决策边界模糊性以及特定标记位置的固有偏见导致的。针对上述问题,基于经验观察我们提出了一种针对LLMs的两阶段分类框架,即利用点对(pairwise)比较方式能够有效降低模糊边界和固有偏见对分类结果的影响。具体来说,我们首先利用self-reduction技术减少候选分类数量,其有助于减少决策空间大小并有助于加快分类速度。然后,我们以对点(pairwise)方式两两比较候选类别,并通过思维链方式挖掘样本与不同类别间的细微差别以区分易混淆类别,从而有效精细化模糊的决策边界以提升分类精度。在已有四个数据集(Banking77, HWU64, LIU54, 和 Clinic150)上实验显示所提针对LLMs的分类模型框架较已有SOTA模型具有更优性能,且其对基于LLMs的不同分类模型具有泛化性,能够一致性提升不同模型的分类准确性。
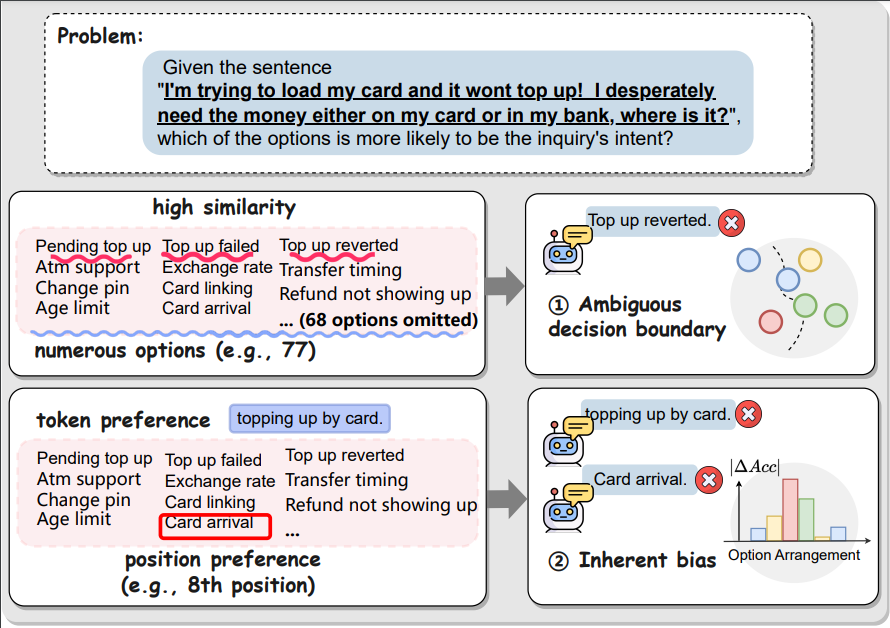
图3:实例分析:大语言模型对于候选分类数量和分类顺序敏感性