华中科技大学自然语言处理工具包(HUST-NLP)是华中科技大学认知计算与智能信息处理实验室(CCIIP)研发的一款轻量级的自然语言处理(NLP)处理套件,其具有统一的数据预处理组件,并提供了多种高级模块,如Transformer、CRF等;在序列标注、文本分类等NLP子任务上,HUST-NLP还封装了各种模型可供直接调用。在兼顾易用性的同时,HUST-NLP在中文分词、命名实体识别、词性标注、和文本分类等多个任务中都能够取得较好的效果。如果你需要快速地部署完成一个NLP任务,或是高效地构建对比模型进行科研,HUST-NLP可能是你很好的选择。
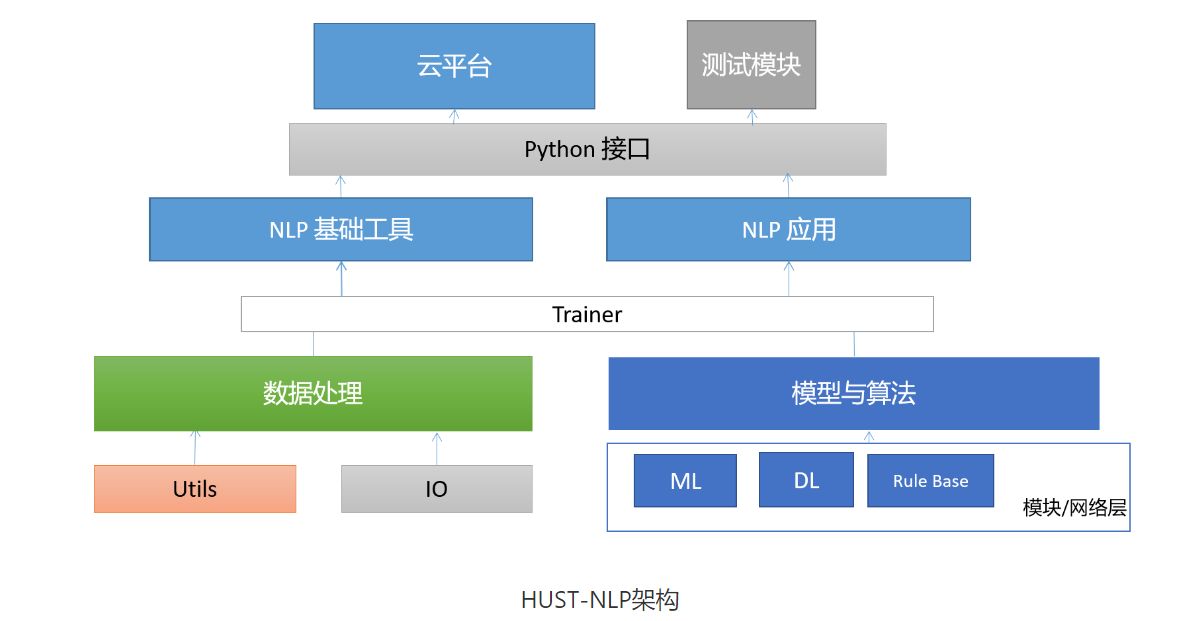
目前HUST-NLP-v1.0版本功能如下:
1. 中文分词
中文分词(Chinese Word Segmentation, CWS)是指将连续的汉字序列切分为词语序列。
注:每个结点即为单独分开的词。
HUST-NLP分词模块性能如下:
数据集 |
F1(%) |
公开数据集 |
人民日报 |
97.77 |
自标注数据集 |
百科 |
98.64 |
知道 |
95.03 |
知乎 |
97.42 |
微博 |
93.93 |
2. 词性标注
词性标注(Part-Of-Speech tagging, POS),是指是对连续的词语序列根据上下文内容进行词性的标注(如动词、名词、形容词等)。
注:括号中表示每个词的词性
HUST-NLP词性标注模块性能如下:
数据集 |
ACC(%) |
公开数据集 |
人民日报 |
98.52 |
自标注数据集 |
百科 |
95.78 |
知道 |
93.36 |
知乎 |
93.19 |
微博 |
94.35 |
3. 命名实体识别
命名实体识别(Named Entity Recognition, NER)是指识别中文文本中具有特定意义的实体指代的边界和类型,主要包括人名、地名、专有名词等。
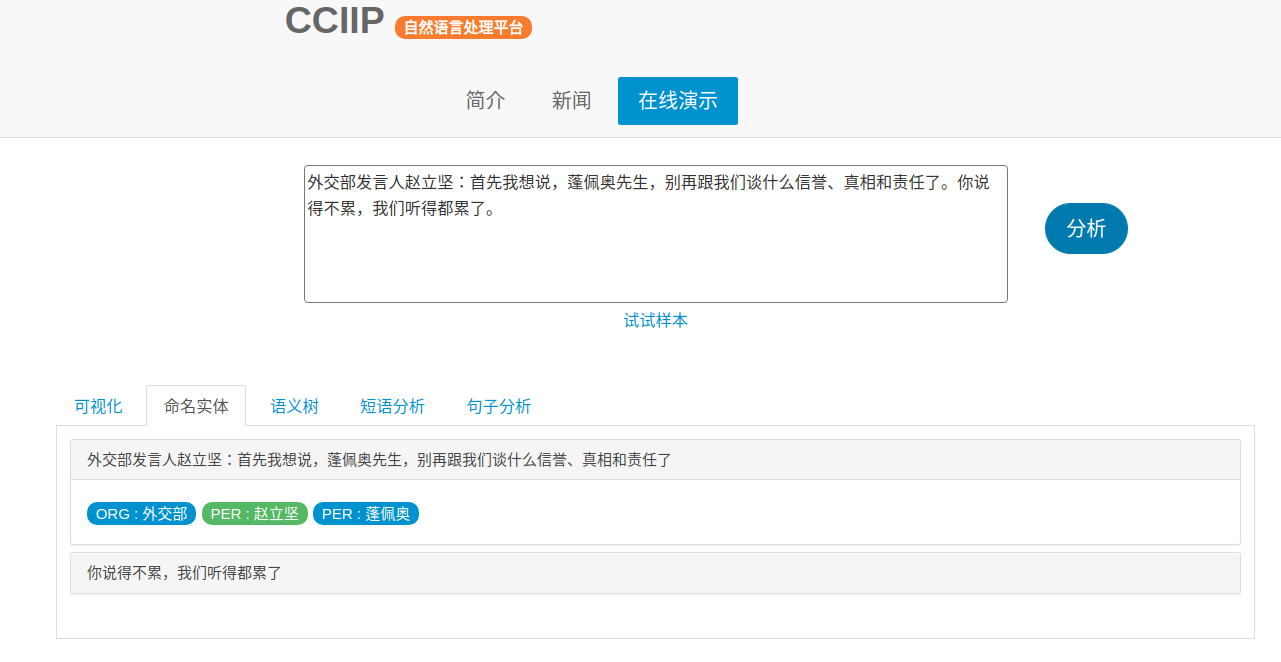
HUST-NLP命名实体识别模块性能如下:
数据集 |
F1(%) |
公开数据集 |
人民日报 |
94.46 |
自标注数据集 |
百科 |
76.75 |
知道 |
73.68 |
知乎 |
79.82 |
微博 |
78.42 |
4. 依存句法分析
依存句法分析(Syntactic Dependency Parsing)是通过分析句子内各语言成分之间的依存关系来解释其句法结构。

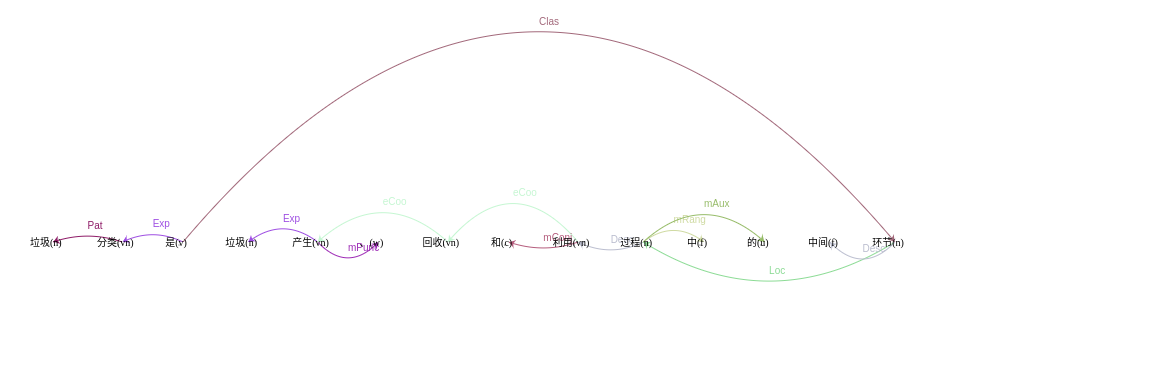
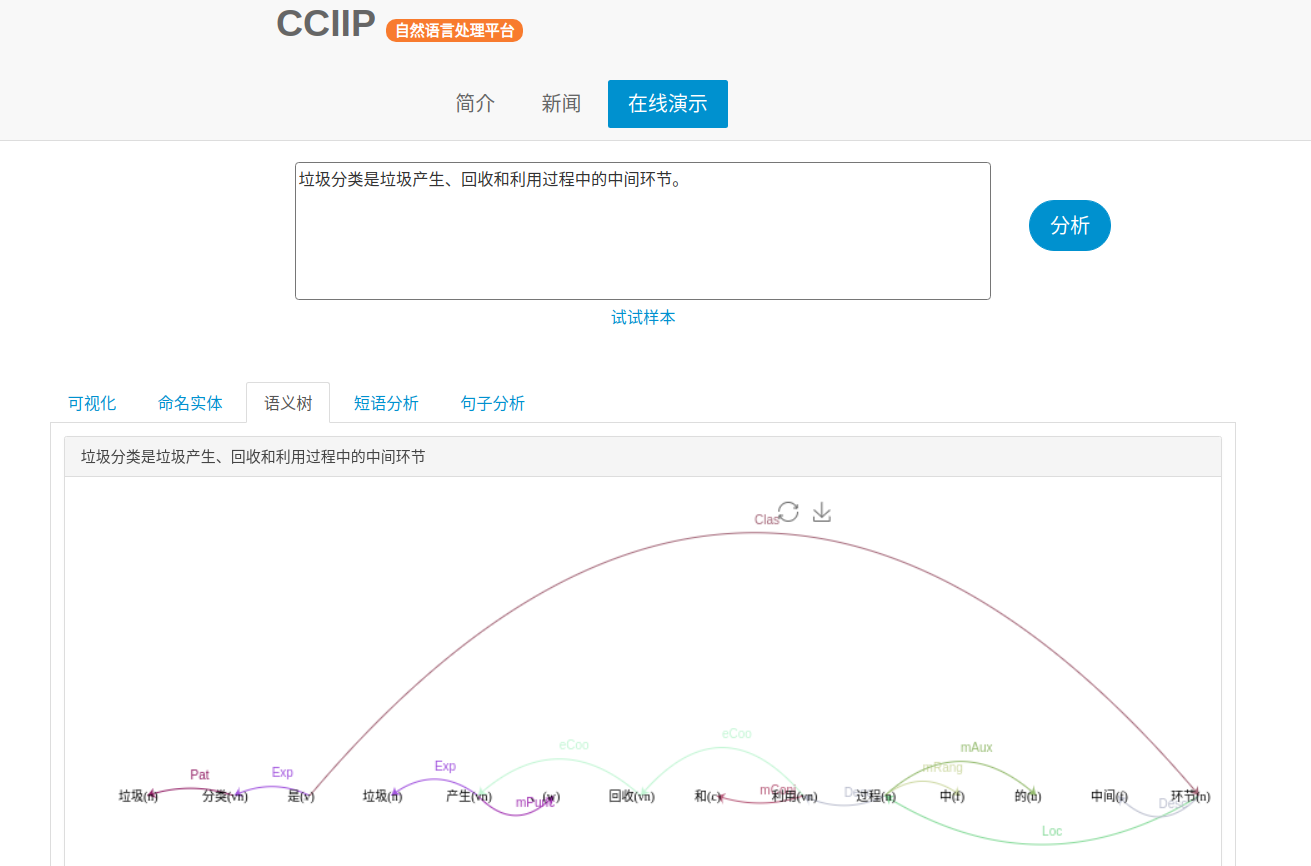
5. 语义依存分析
语义依存分析(Semantic Dependency Parsing)是对句子各个语言单位之间的关联进行分析,其结果一般通过语义树来展现。
6. 句子分析
句子分析可分为以下部分,肯定/否定句判别,特指问句分类,句子分类,主谓宾标注。
(1)肯定/否定句判别:判断一个句子表达的是“肯定”还是“否定”的含义。
(2)特指问句分类:对特指问句进行提问类型的细化分类。
(3)句子分类:对每个句子进行类型上的区分,如陈述句、是非问句、正反问句、感叹句、特指问句等
(4)主谓宾标注:对每个句子的句法结构进行解析,将其主谓宾定状补的结构表示出来。
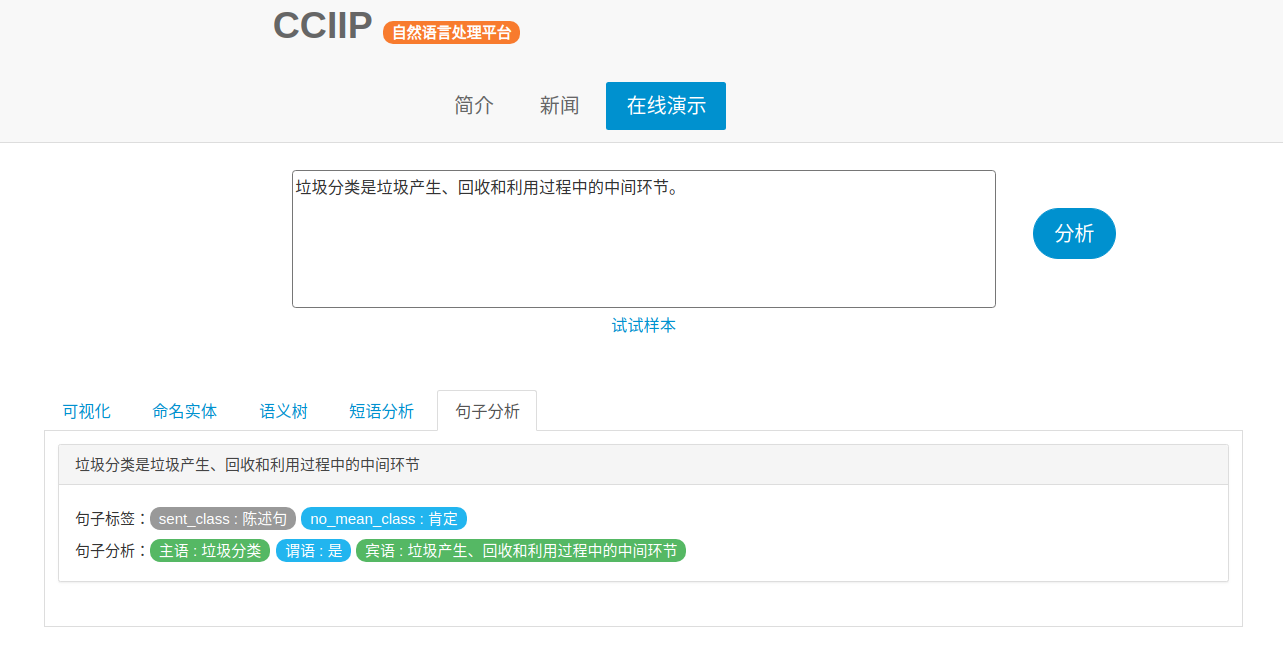
HUST-NLP句子分析模块性能如下:
自标注数据集 |
百科 |
知道 |
|
Precision(%) |
Recall(%) |
F1 |
Precision(%) |
Recall(%) |
F1 |
肯定/否定判别 |
0.9948 |
1.0000 |
0.9974 |
0.9845 |
0.9948 |
0.9896 |
特指疑问句 |
0.0000 |
0.0000 |
0.0000 |
0.6196 |
0.5816 |
0.6000 |
句子分类 |
1.0000 |
1.0000 |
1.0000 |
0.8250 |
0.8250 |
0.8250 |
主谓宾标注 |
0.6532 |
0.6726 |
0.6628 |
0.5105 |
0.4449 |
0.4754 |
自标注数据集 |
知乎 |
微博 |
|
Precision(%) |
Recall(%) |
F1 |
Precision(%) |
Recall(%) |
F1 |
肯定/否定判别 |
0.9848 |
1.0000 |
0.9924 |
0.9897 |
0.9897 |
0.9897 |
特指疑问句 |
0.7546 |
0.7365 |
0.7455 |
0.6667 |
0.7273 |
0.6957 |
句子分类 |
0.9650 |
0.9650 |
0.9650 |
0.8900 |
0.8900 |
0.8900 |
主谓宾标注 |
0.6375 |
0.5767 |
0.6056 |
0.5516 |
0.4843 |
0.5158 |